Retrieval-Augmented Generation for Large Language Models: A Survey
1. Overview of RAG
典型的RAG模型如图1所示
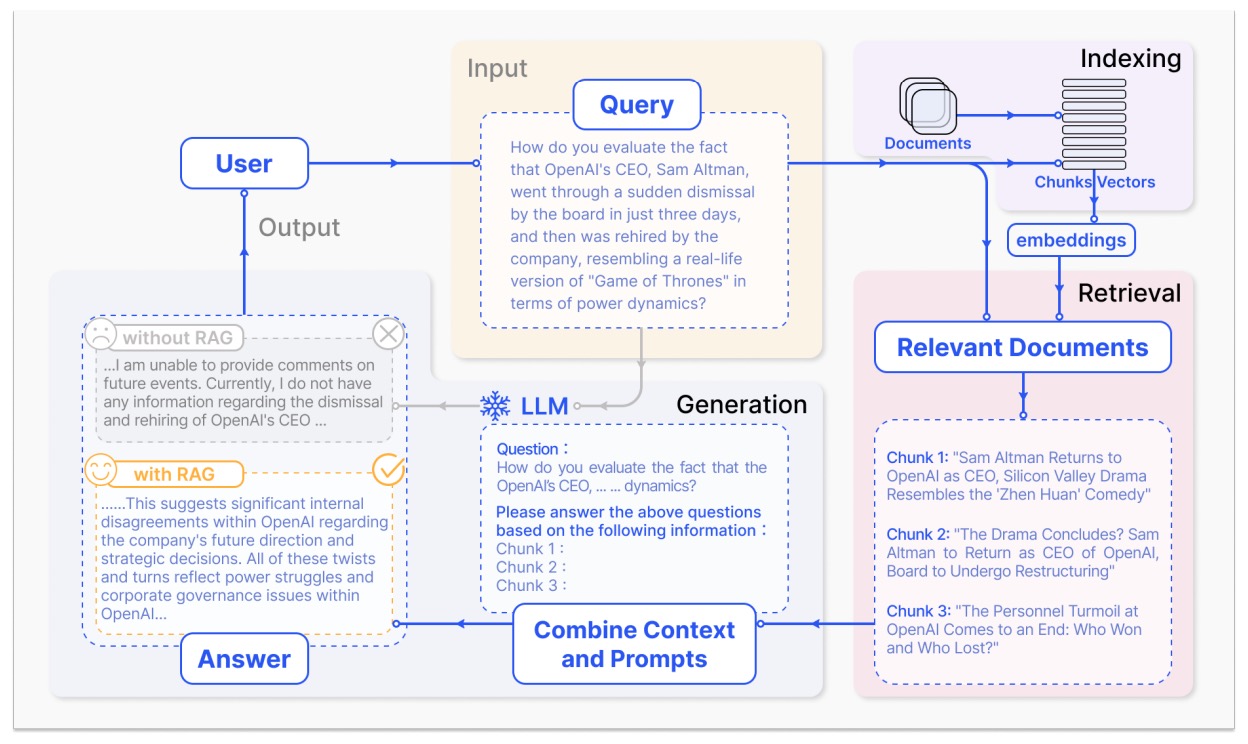
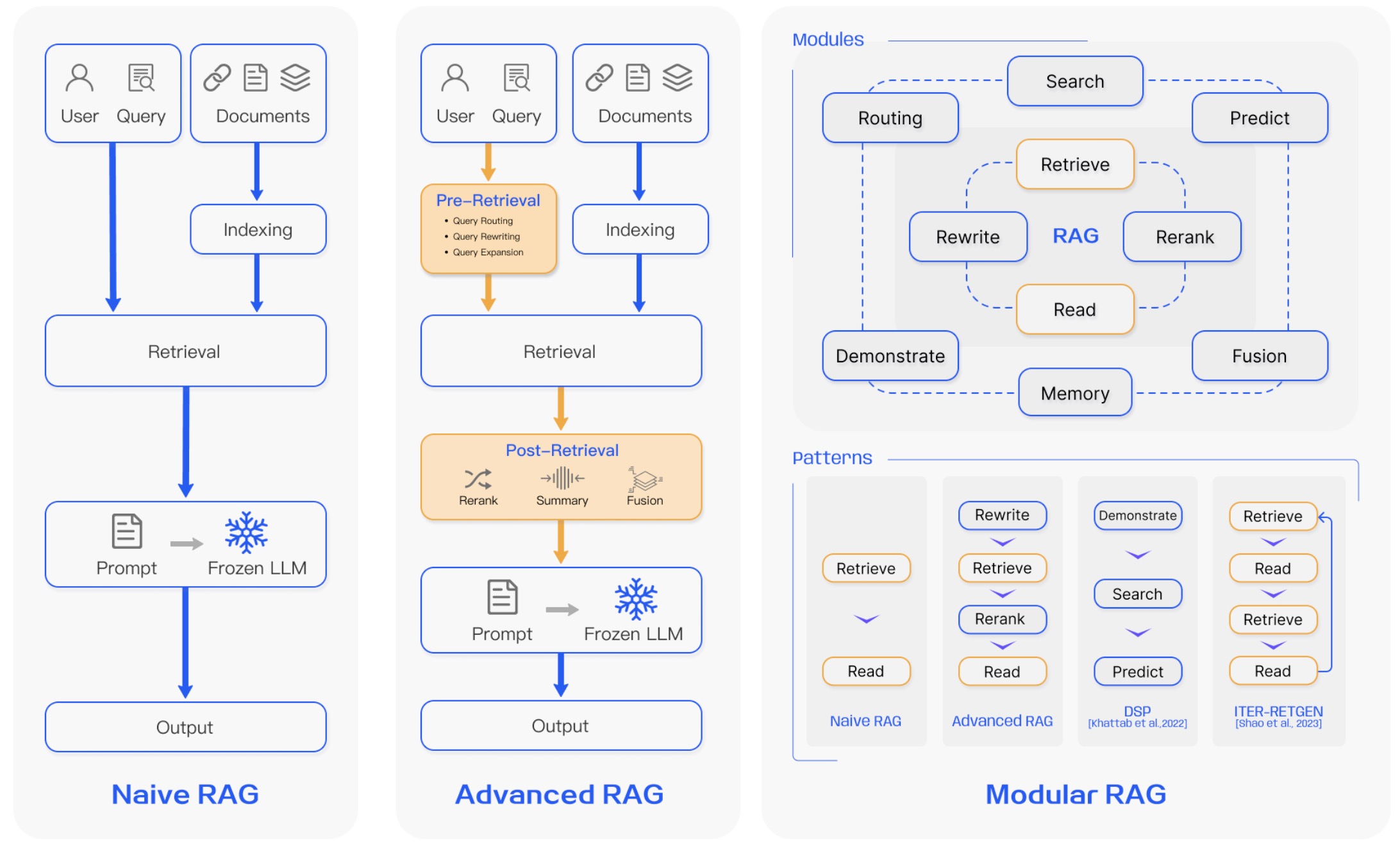
1.1 Naive RAG
Naive RAG为传统的RAG方法,主要流程包括:索引,检索,生成。
- 索引(Indexing):将文档(PDF,HTML,Word,Markdown)切分成chunks,每个chunk为一段文本,使用一个词向量模型将每个chunk编码成向量表征存储在向量数据库中。这一步是为了高校地搜索查找待检索片段。
- 检索(Retrieval):基于用户的一条query,RAG系统使用相同的编码模型将query编码成对应向量表征,用query向量表征与向量数据库中的所有向量计算相似度,选择相似度最高的K个chunks,这些chunks将被用于扩充query的prompt。
- 生成(Generation):用户的query和被选择的chunks被整合成连贯的prompt输入给LLM,LLM基于扩充后的prompt生成结果。
1.2 Advanced RAG
Advanced RAG引入一些改进来解决Navie RAG存在的一些问题,主要聚焦在提升检索质量,一般使用pre-retrieval和post-retrieval两种策略。
- pre-retrieval:在这个阶段,主要目标是优化索引结构以及初始query。
- 优化索引:常用的策略有增强数据细粒度,优化索引结构,添加元数据,对齐优化,混合检索。
- 优化初始query:常用的策略有query transformation,query expansion等。
- post-retrieval:当相关内容已经被检索后,将其与初始query有效结合是至关重要的一步。post-retrieval过程中主要的方法包括:chunks重排,chunks内容压缩。
- chunks重排:调整被检索到的内容(chunks)在最终prompt中的位置,让更相关的chunks排在prompt的边缘(非中间,中间更容易被llm忽略),这个策略在LlamaIndex,LangChain,HayStack中均有使用。
- chunks内容压缩:将所有检索到的内容(chunks)全部输入llm容易导致信息过载(因为会包含很多无关或者冗余的信息),对此,chunks内容压缩主要聚焦在选择重要信息,缩短检索内容。
1.3 Modular RAG
模块化RAG相比前两种范式提供更好的适应性和多功能性。其往往结合不同的策略来优化其组成部分,比如:添加一个搜索模块,通过微调精进检索器等。
- 引入新模块:搜索模块(Search Module)可以用于搜索外部资源(搜索引擎、数据库、知识图谱),使用LLM生成的搜索指令和查询语句处理;RAG-Fusion用于处理传统搜索的限制问题,使用multi-query策略将用户query从不同角度扩充;记忆模块(Memory Module)用于提升LLM的记忆来指导检索;路由模块(Routing)等等
- 引入新模式:Rewrite-Retrieve-Read模型通过引入rewriting module和一个语言模型反馈机制来更新rewriting model,提升性能;Generate-Read,Recite-Read等等。
2. Retrieval Part
2.1 检索资源
从检索内容的数据上来看包含以下几种:
- 无结构化数据:文本,语料库,例如Wikipedia Dump,HotpotQA,DRP;多语种文本,特别领域文本等
- 半结构化数据:PDF,这种数据包含文本和表格,对于RAG系统而言处理起来更具挑战,一般会用到LLM生成Text-2-SQL指令查询表格中的数据,工作如TableGPT等。
- 结构化数据:知识图谱,工作如KnowledGPT,G-Retriever等。
- LLMs生成内容
从检索的粒度来看,包含以下几种:
- 对于文本,检索粒度涵盖:Token,短语,句子,Chunks,文章
- 对于知识图谱,检索粒度包含:实体,三元组,子图
2.2 索引的优化
在索引这一环节,文章将被处理,分割并转变成向量表征被存储在向量数据库中。索引结构的质量决定着在检索过程中能否获取正确的内容。
- Chunking Strategy:最常用的方法是将文档切分成固定token数的chunk(100,256,512)。越大的chunk能够捕获更多的内容,但也会带来更多噪音,处理更长时间,成本更高;越小的chunk相反。划分chunk存在破坏完整句子的问题,解决该问题的工作有Small2Big等。
- Metadata Attachments:chunk可以由元数据(如:page number,file name,author,category timestamp等)扩充,从而检索过程可以使用元数据进行过滤,缩小检索范围。
- Structural Index:
- 分层索引结构
- 知识图谱索引
2.3 Query的优化
- Query扩充:
- Multi-Query:通过LLM将query扩充成多个,然后并行处理这些queries
- Sub-Query:对于复杂问题,可以将问题拆解成系列子问题
- Chain-of-Verification(CoVe)
- Query Transformation:
- Query Rewrite:有些原始queries对于LLM检索来说并不是最优。因此prompt LLM来重写queries,工作如Rewrite-retrieve-read等
- Query Routing
2.4 词向量模型(retriever)
从向量编码器角度分包含sparse encoder和dense encoder
- sparse encoder:
- TF-IDF
- BM25
- dense retriever:
- BERT-based PLM
3. Generation Part
在完成检索部分后,把所有检索到的信息直接输入LLM来获取答案往往并不是最合理的方案。在生成阶段,一般会从两个方面引入一些调整:调整检索的内容、调整LLM。
3.1 Context Curation
冗余信息会影响LLM最终的生成结果,通常,LLM会把注意力倾向长文本的开端和结尾,而容易忘记中间的部分。因此在RAG系统中,我们通常需要进一步处理检索到的信息。
- Reranking:重排chunks的顺序
- rule-based methods:Diversity,Relevance,MRR
- model-based methods:BERT series(SpanBERT),Cohere rerank,bge-reranker-large
- Context Selection/Compression:对检索内容的筛选和压缩
- Reducing the number of documents
3.2 LLM Fine-tuning
对生成式LLM进行微调,主要适用特定场景下的生成,一般的PLM可能对这些场景了解程度不够,因此需要微调来辅助LLM生成。
4. Augmentation Process in RAG
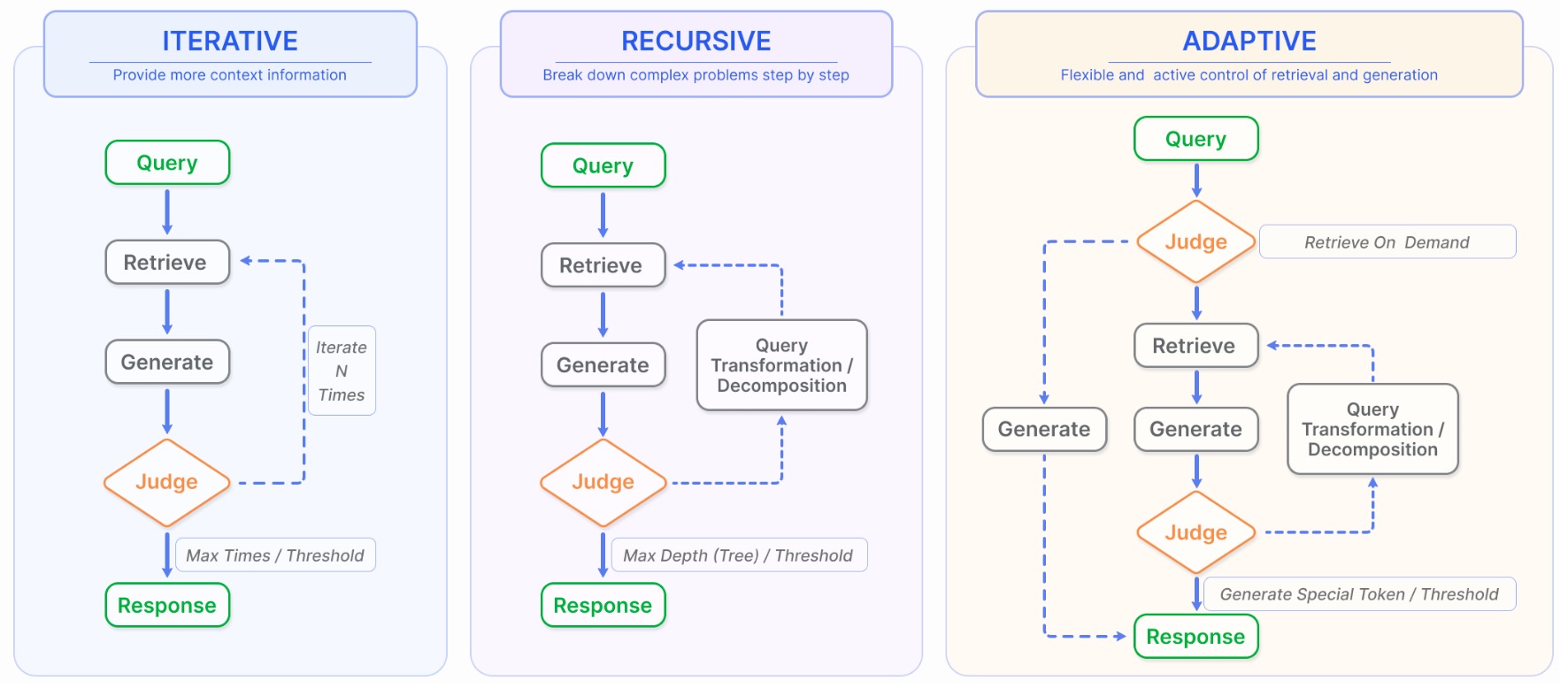
常规的RAG流程通过只包含一次检索步骤,然后接着一步生成步骤,对于复杂任务或多步推理场景这种方式局限性较大,因此有优化的检索过程来解决这些问题。
4.1 迭代检索(Iterative Retrieval)
迭代检索过程中,知识库会基于初始query以及当前生成的文本被重复搜索,为LLM生成提供更全面的信息。相关工作:ITER-RETGEN等。
4.2 递归检索(Recursive Retrieval)
递归检索通常用于信息检索来提升检索结果的深度和相关性。该过程会基于过往检索的结果迭代优化检索queries。相关工作:IRCoT,ToC等。
4.3 适应性检索(Adaptive Retrieval)
适应性检索通过让LLMs能够主动决策最优检索的时刻以及检索的内容来优化RAG系统,提升检索信息的相关度以及效率。相关工作:Flare,Self-RAG,AutoGPT,Toolformer,Graph-Toolformer,WebGPT等。
基于query的RAG方法(query-based)
1. REALM: Retrieval-Augmented Language Model Pre-Training
Guu et al. (2020) 提出REALM,一种经典的query-based的RAG方法,文章使用BERT模型作为检索器:
将检索的文本$z$与query $x$拼接用于answer $y$的生成。
2. REPLUG: Retrieval-Augmented Black-Box Language Models
Shi et al. (2024) 提出一种针对黑盒模型的query-based RAG方法
- 无训练Method
基于输入query $x$,选定现有检索器,文档库$\mathcal D={d_1,\cdots,d_m}$,检索器为编码器结构,被用来同时对query和文档进行编码。$\text{E}(d)$为编码器最后一层隐藏表征在所有token上的表征均值。计算query表征与所有文档表征的余弦相似度:
选择其中相似度分数最高的$k$个文档构成集合$\mathcal D^\prime\sub\mathcal D$。这里为了高效检索,提前计算每个文档的向量表征并构建FAISS索引。
根据前面计算的相似度分数计算每个相关文档的权重:
为了同时利用所有相关文档,切不超出模型最大输入长度,作者使用加权解码,用上述$\lambda(d,x)$作为权重:
其中$d\ \circ\ x$表示文档$d$和query $x$的拼接。
- 带训练Method
作者同时提出一种训练方法主要用于对齐检索器与生成器,训练过程中只更新检索器参数(针对黑盒模型)。首先用初始检索器检索$k$个最相关文档,与之前类似的,计算每个文档的权重分数:
其中$\gamma$为超参数控制softmax的温度,计算得到的$P_R(d\vert x)$分布代表了检索器的检索分布。紧接着,给定ground truth $y$,对于每个相关文档,计算生成器在ground truth部分的LM perplexity $P_{LM}(y\vert d,x)$,并得到生成器的分布:
其中$\beta$也是调节softmax温度的超参数。最终根据上面检索器的分布$P_R(d\vert x)$和生成器的分布$Q(d\vert x,y)$计算两者的KL-divergence并作为损失函数优化检索器参数:
其中$\mathcal B$是query集合,每个query $x$均有一个ground truth $y$。注意到由于检索器参数更新,使得预先存好的所有文档向量表征会有所变化,为了高效训练,作者采用的方案是每训练$T$个steps后重新计算所有文档的向量表征。
3. In-Context RALM: In-Context Retrieval-Augmented Language Models
Ram et al. (2023) 提出一种基于in-context的RAG方法,该方法主要使用了Retrieval Stride和Retrieval Query Length两个trick。
- In-Context RALM
不同于普通的query-based RAG方法只基于query检索一次文档库,In-Context RALM会在生成过程中不断基于当前的生成结果去多次检索文档库,定义目前生成的文本(包括query)为$x_{\lt i}$,使用$x_{\lt i}$检索得到的文档内容为$\mathcal R_\mathcal C(x_{\lt i})$,那么In-Context RALM的生成过程可以通过如下公式定义:
- Retrieval Stride
由于频繁检索文档库会带来比较高的资源消耗,且降低生成速度,因此作者提出Retrieval Stride的概念,即每生成$s(s>1)$个token后进行一个检索,这样RALM的生成过程为:
其中$n_s=n/s$为检索的次数(Retrieval Strides)。实验结果表明使用较小的$s$(尽可能多的增加检索次数)会比使用较大的$s$效果好,但是会增加时间成本。
- Retrieval Query Length
作者指出尽管检索query原则上取决于所有的prefix tokens $x_{\le s\cdot j}$,但是与生成token最相关的信息往往都聚集在prefix tokens的末尾,如果检索query太长那么这些信息会被稀释。对此作者提出Retrieval Query Length的概念,即控制query长度不超过$\ell$,当query长度超过$\ell$时截取整个query的最后$\ell$个token,即$q_j^{s,\ell}:=x_{s\cdot j-\ell+1},\cdots,x_{s\cdot j}$,应用上述trick后的生成过程定义如下:
4. SELF-RAG: Learning to Retrieve, Generate, and Critique Through Self-Reflection
Asai et al. (2024) 提出了一种基于反馈的RAG框架,主要通过引入Critic模型和Generator模型,Critic模型会在Generator模型生成前判断是否需要进行检索,如果不需要则直接让Generator生成下一个sequence(文章以一个完整的sequence为单位作为检索间隔),否则使用检索器检索相关文档,之后会让Critic判别每个文档的相关性与是否支持回答该问题等信息。作者在模型词表引入一些reflection tokens作为Critic模型的判别输出结果,通过基于prompt GPT4的方式获取有效监督数据并训练Critic模型以及Generator模型(蒸馏GPT4模型知识)。SELF-RAG整体流程框架如图4所示。
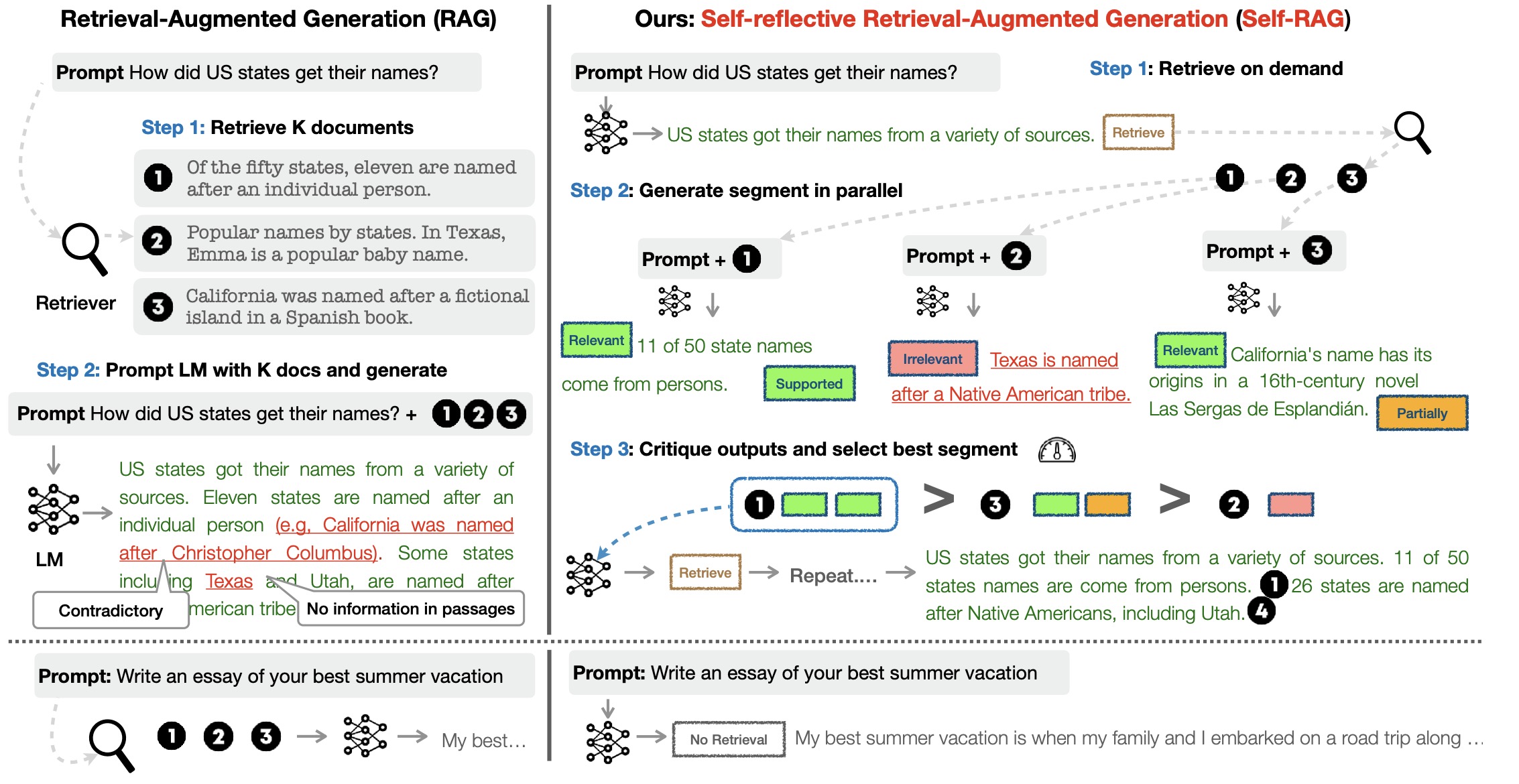
- 四类reflection tokens

- SELF-RAG Inference算法

- SELF-RAG Training算法(Critic $\mathcal C$ 和Generator $\mathcal M$)

$$ \max_\mathcal C\mathbb E_{((x,y),r)\sim\mathcal D_{critic}}\log p_\mathcal C(r\vert x,y),\ r\ \text{for reflection tokens} $$
Eq2:
$$ \max_\mathcal M\mathbb E_{(x,y,r)\sim\mathcal D_{gen}}\log p_\mathcal M(y,r\vert x) $$
基于表征的RAG方法(Representation-based)
1. FID: Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
Izacard et al. (2021) 提出一种基于representation的RAG方法,作者使用encoder-decoder模型(BART),对于检索器,使用BM25和DPR两种方法检索相关文档,对每个文档都分别使用encoder编码成隐空间表征,并将所有的表征拼接在一起输入decoder解码出answer,作者命名这类结构为Fusion-in-Decoder,结构示意图如图8所示。
作者在处理数据时,在问题(question),文档标题(title),文档内容(context)之前都添加了特殊tokens:"$\text{question:}$",$\text{title:}$,$\text{context:}$。

References
[1] Gao et al. “Retrieval-Augmented Generation for Large Language Models: A Survey” arXiv preprint arXiv:2312.10997 (2023)
[2] Guu et al. “Retrieval Augmented Language Model Pre-Training” ICML 2020.
[3] Shi et al. “REPLUG: Retrieval-Augmented Black-Box Language Models” NAACL 2024.
[4] Ram et al. “In-Context Retrieval-Augmented Language Models ” TACL 2023.
[5] Asai et al. “Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection” ICLR 2024.
[6] Izacard et al. “Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering” EACL 2021.