Overview
这篇文章只看 2026-01-01 到 2026-03-29 之间首次公开、且由厂商官方开源的基础模型或明确模型家族变体。整理时我只接受下面几类一手材料:
- 官方技术博客 / 官方发布页
- 官方技术报告 / arXiv / model card
- 官方 GitHub / Hugging Face / ModelScope
如果某个字段没有被官方明确披露,我会直接写成 官方未披露,而不是用二手解读把空白补满。
还有一个边界需要先说明:2026 Q1 里不少 release 实际上是“同一架构的一组尺寸变体”或“旧家族在 2026 年发布的新 checkpoint”。为了让文章既尽量全,又能把 architecture 讲清楚,我采用下面的组织原则:
- 同一轮 release、同一套核心架构、只是参数规模不同的,合并为一个模型家族目录,目录里列 variant。
- 如果虽然同属一家厂商,但 block 结构、路由方式、模态连接器或者训练目标已经发生明显变化,就拆成单独目录。
- 某些 2026 Q1 新变体的技术细节来自 2025 末先行公开的家族技术报告,这类条目我会明确标注“2026 发布的变体,架构说明引用家族官方报告”。
How To Read
文章分成三部分:
LLM:以通用语言能力、编码、agent 推理为主的基础模型。少数模型虽然已经支持图像输入,但官方定位仍然是 general foundation model,我放在这一组。VLM:以视觉理解、文档理解、OCR、视觉问答为主的模型。Other Multimodal:音频、语音、图像生成 / 编辑、computer-use agent、原生离散多模态等不适合塞进前两组的模型。
每个模型目录都按同一个模板写:
Release & Open SourcesArchitectureParameters & HyperparametersTrainingKey TakeawaysLinks
Scope Notes
Google的TranslateGemma/MedGemma属于官方开放权重但 gated access 的 release。官方文档能确认发布时间、模型尺寸和训练目标,但逐层 config 公开得不如其他模型完整,因此我会明确区分“继承 Gemma 主干的已知部分”和“本次 release 未重复公开的细节”。IBM Granite与LongCat-Image这类家族,有些核心架构论文首发早于 2026,但本文讨论的是 2026 Q1 新发布的官方开源 checkpoint / 变体。
LLM
Xiaomi / 小米
MiMo-V2-Flash
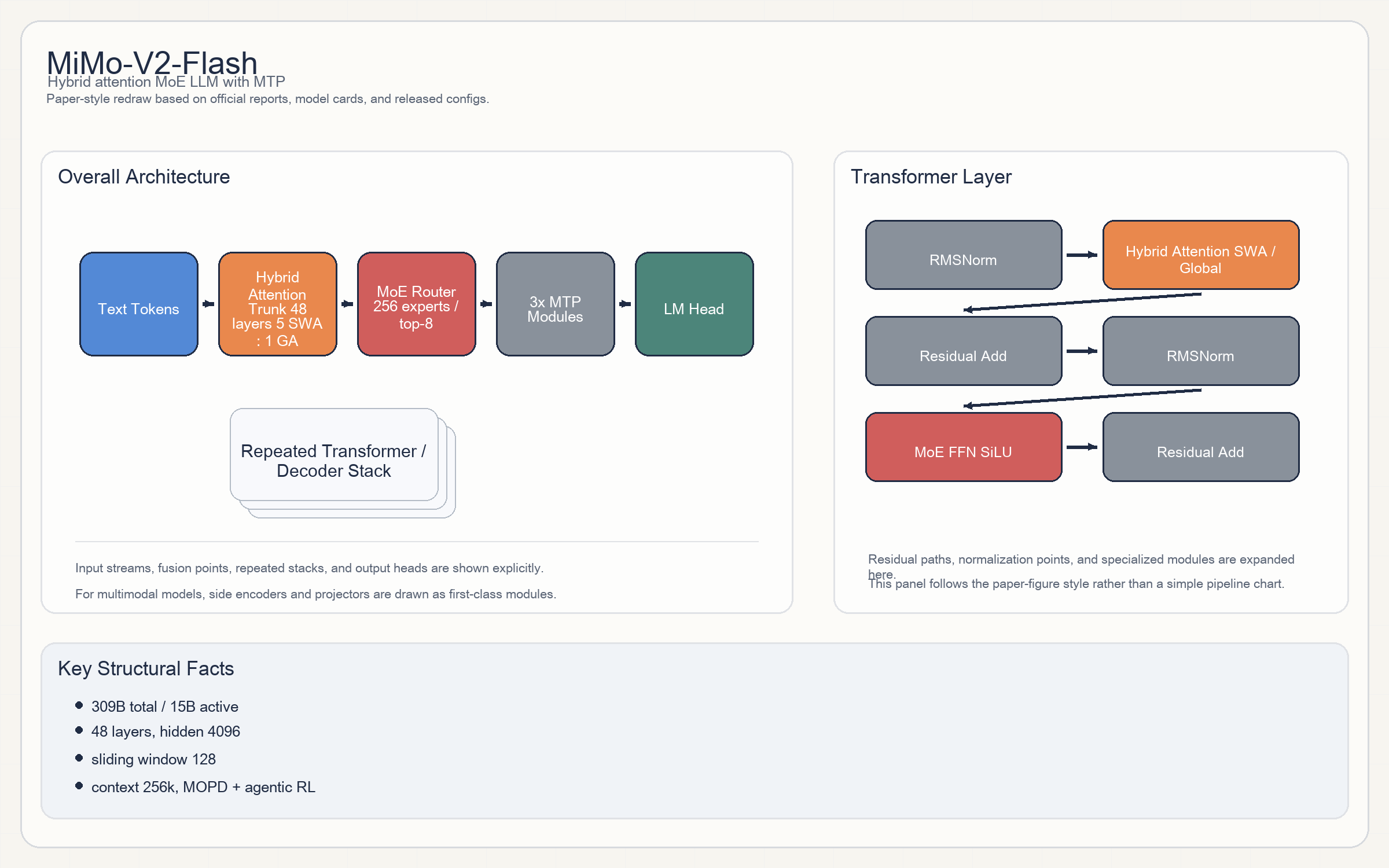
Release & Open Sources
- 发布时间:官方技术报告
arXiv:2601.02780,官方仓库在 2026 年 1 月公开。 - 形态:decoder-only
MoELLM。 - 官方开源入口:GitHub、Hugging Face、官方博客同时可用。
Architecture
MiMo-V2-Flash是一个以高吞吐 agent 推理为目标的MoE语言模型。整体结构是token embedding -> 48-layer transformer trunk -> MTP heads -> LM head。- 主干 block 采用 pre-norm transformer。每层可以概括成:
RMSNorm -> Hybrid Attention -> Residual -> RMSNorm -> MoE FFN -> Residual。 - attention 不是纯 full attention,而是官方强调的
Hybrid Attention:Sliding Window Attention与Global Attention交织使用,报告给出的比例是SWA:GA = 5:1,window size 为128。这使它把长上下文能力和 KV cache 成本一起优化。 - MLP / expert 部分是稀疏 expert。根据官方 config,路由专家数
256,每 token 激活top-8,激活函数是SiLU。 - 模型还带了
Multi-Token Prediction模块,用于更快推理和更高 RL rollout 效率。官方把它当成 M2.5 之外另一条很重要的效率支柱。
Parameters & Hyperparameters
- 总参数 / 激活参数:
309B total / 15B active。 - 层数 / hidden size:
48 layers / 4096 hidden。 - attention heads:
64 Q heads / 4 KV heads。 - FFN intermediate:
16384。 - context:原生训练
32k,支持到256k。 - 其他关键值:
rope_theta = 5e6,sliding_window = 128。
Training
- 预训练:官方给出
27T tokens,并明确提到 FP8 mixed precision 与长上下文训练。 - 后训练:官方把
MOPD(multi-teacher on-policy distillation)和大规模agentic RL作为核心 recipe,对 coding、tool use、SWE-Bench 一类任务做强化。
Key Takeaways
- MiMo-V2-Flash 最重要的不是参数总量,而是它把
Hybrid Attention + top-8 MoE + MTP + agentic RL绑成了一套面向真实 agent throughput 的统一设计。
Links
- 博客:MiMo-V2-Flash Blog
- 技术报告:MiMo-V2-Flash Technical Report
- 官方仓库:XiaomiMiMo/MiMo-V2-Flash
- 模型页:XiaomiMiMo/MiMo-V2-Flash
Moonshot AI / 月之暗面
Kimi-K2.5
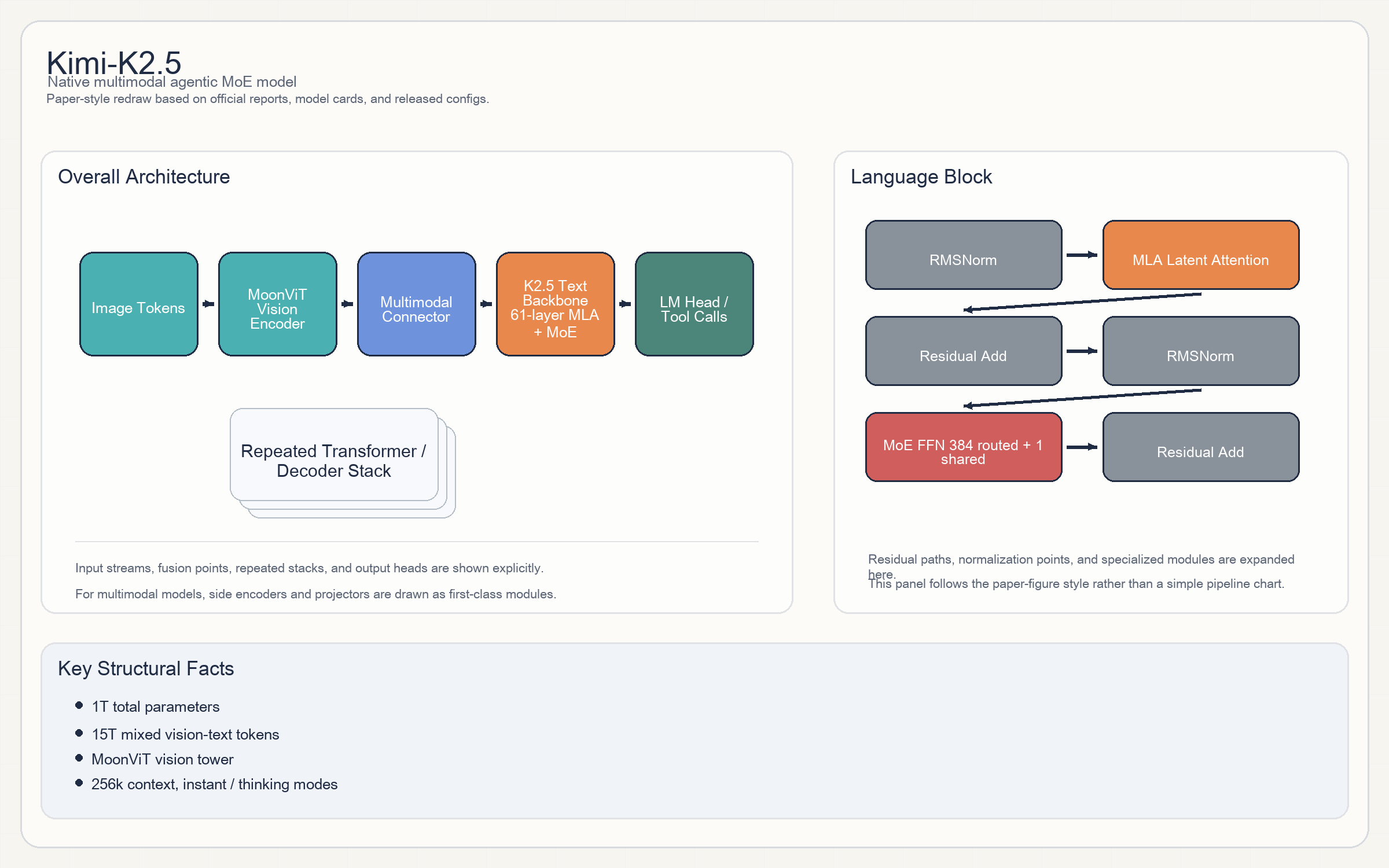
Release & Open Sources
- 发布时间:
2026-01-01。 - 形态:Moonshot 把它定义为
native multimodal agentic model,但在能力定位上仍然是通用基础模型,所以我放在 LLM 组里。 - 官方开源入口:官方 blog、paper、GitHub、Hugging Face 全齐。
Architecture
- 整体上是
MoonViT vision encoder + multimodal connector + Kimi text backbone。文本主干是一个超大规模MoE decoder。 - 官方 config 显示其语言主干继承了
DeepSeek-V3风格实现,采用MLA(Multi-head Latent Attention)而不是传统 MHA/GQA。 - 单个文本 block 可以概括成:
RMSNorm -> MLA -> Residual -> RMSNorm -> MoE FFN -> Residual。激活函数为SiLU。 - Expert routing 是稀疏路由:
384routed experts、1shared expert、每 token 激活8experts。 - K2.5 的官方模型卡同时明确了 vision tower 是
MoonViT,patch size14,并把这部分视为原生视觉能力的一部分,而不是轻量外挂 projector。
Parameters & Hyperparameters
- 总参数:官方模型卡给的是
1T total parameters。 - hidden / layers / heads:
7168 hidden / 61 layers / 64 attention heads。 - context:
256k。 - FFN / expert size:dense intermediate
18432,expert intermediate2048。 - 视觉编码器:官方卡片写明
400M量级MoonViT。
Training
- 预训练:官方写明是在
Kimi-K2-Base之上继续预训练,使用约15T混合视觉与文本 token。 - 后训练:官方重点放在 visual reasoning、agentic tool use、instant / thinking 两种工作模式;公开文档没有把 SFT / RL token 量拆开。
Key Takeaways
- K2.5 的关键不是“在文本 LLM 上补一个视觉编码器”,而是把
MLA MoE text trunk + MoonViT + agentic post-training合成了一个原生多模态基础模型。
Links
- 博客:Kimi K2.5 Tech Blog
- 技术报告:arXiv:2602.02276
- 官方仓库:MoonshotAI/Kimi-K2.5
- 模型页:moonshotai/Kimi-K2.5
Meituan / 美团
LongCat-Flash-Thinking-2601
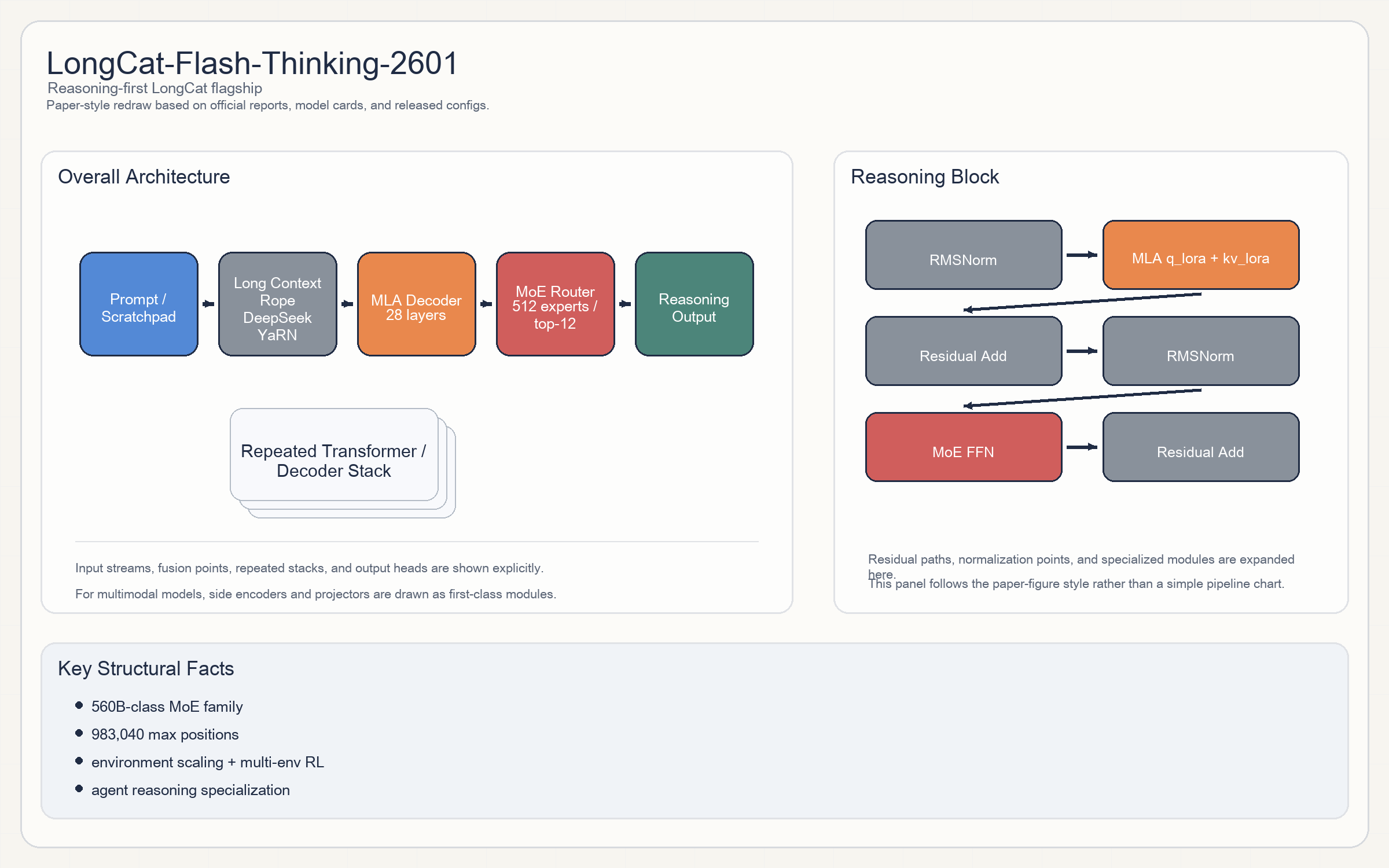
Release & Open Sources
- 发布时间:
2026-01-14。 - 形态:面向 agent reasoning 的
MoE推理模型。 - 官方来源:Hugging Face model card、官方 GitHub、技术报告 PDF。
Architecture
- LongCat-Flash-Thinking-2601 是
LongCat系列在 2026 Q1 的主力推理模型。总体结构是decoder-only MoE。 - 每层的核心 block 由
MLA attention + MoE FFN组成,仍是 pre-norm residual 组织。配置文件给出的关键特征包括q_lora_rank、kv_lora_rank、attention_method = MLA,说明它把低秩 Q/KV 路径和 MLA 一起用了。 - Expert routing 规模非常大:
512 routed experts,每 tokentop-12。激活函数报告和实现都以SiLU为主。 - 这一版最显著的是超长 context:通过
DeepSeek YaRN风格的 rope scaling 把最大位置扩到接近1Mtoken。
Parameters & Hyperparameters
- 官方 README 把它称为
560B级 open-source MoE 模型。 - config 可确认:
6144 hidden、64 attention heads、512 experts、top-12、983,040max positions。 - 其他关键值:
rope_theta = 1e6,q_lora_rank = 1536,kv_lora_rank = 512。
Training
- 官方报告重点讲的是
environment scaling与multi-environment RL,说明其 post-training 明显偏向 agent / search / long-horizon reasoning。 - 训练数据量官方没有在公开 README 中给出完整 token 数,只明确强调了多环境 RL。
Key Takeaways
- 这类 LongCat Flash Thinking 模型的价值不只是参数更大,而是把
MLA + 大规模 MoE + 接近 1M context + 多环境 RL组合成 agent-first 的推理模型。
Links
- 技术报告:LongCat Flash Thinking 2601 Technical Report
- 模型页:meituan-longcat/LongCat-Flash-Thinking-2601
- 仓库:meituan-longcat/LongCat-Flash-Thinking-2601
LongCat-Flash-Lite

Release & Open Sources
- 发布时间:
2026-01-27。 - 形态:LongCat 的轻量 reasoning 模型。
Architecture
- 依然是 decoder-only sparse model,但这条线的重点从“堆更大 MoE”转向
MoE + N-gram Embedding的高效率设计。 - block 仍然是
Norm -> MLA / attention -> Residual -> Norm -> sparse FFN -> Residual。 - 配置可确认:
256 routed experts、top-12、3072 hidden、32 heads。 - LongCat 官方在 README 里直接把它描述为“a better alternative to MoE scaling”的实验,说明这条线的重点在效率而不是极限尺寸。
Parameters & Hyperparameters
3072 hidden / 14 layers / 32 heads。256 experts / top-12。327,680context。ngram_vocab_size_ratio = 78,emb_neighbor_num = 4,这是 Lite 版最有辨识度的附加结构。
Training
- 技术报告
arXiv:2601.21204公开。 - 公开材料强调 reasoning 和 scaling efficiency,但没有像 MiMo 那样公开完整预训练 token 数。
Key Takeaways
- Flash-Lite 的意义在于:它不是简单缩小 LongCat-Flash-Thinking,而是尝试证明更聪明的 token / embedding 设计可以部分替代粗暴扩张的 MoE 尺寸。
Links
LongCat-Flash-Prover
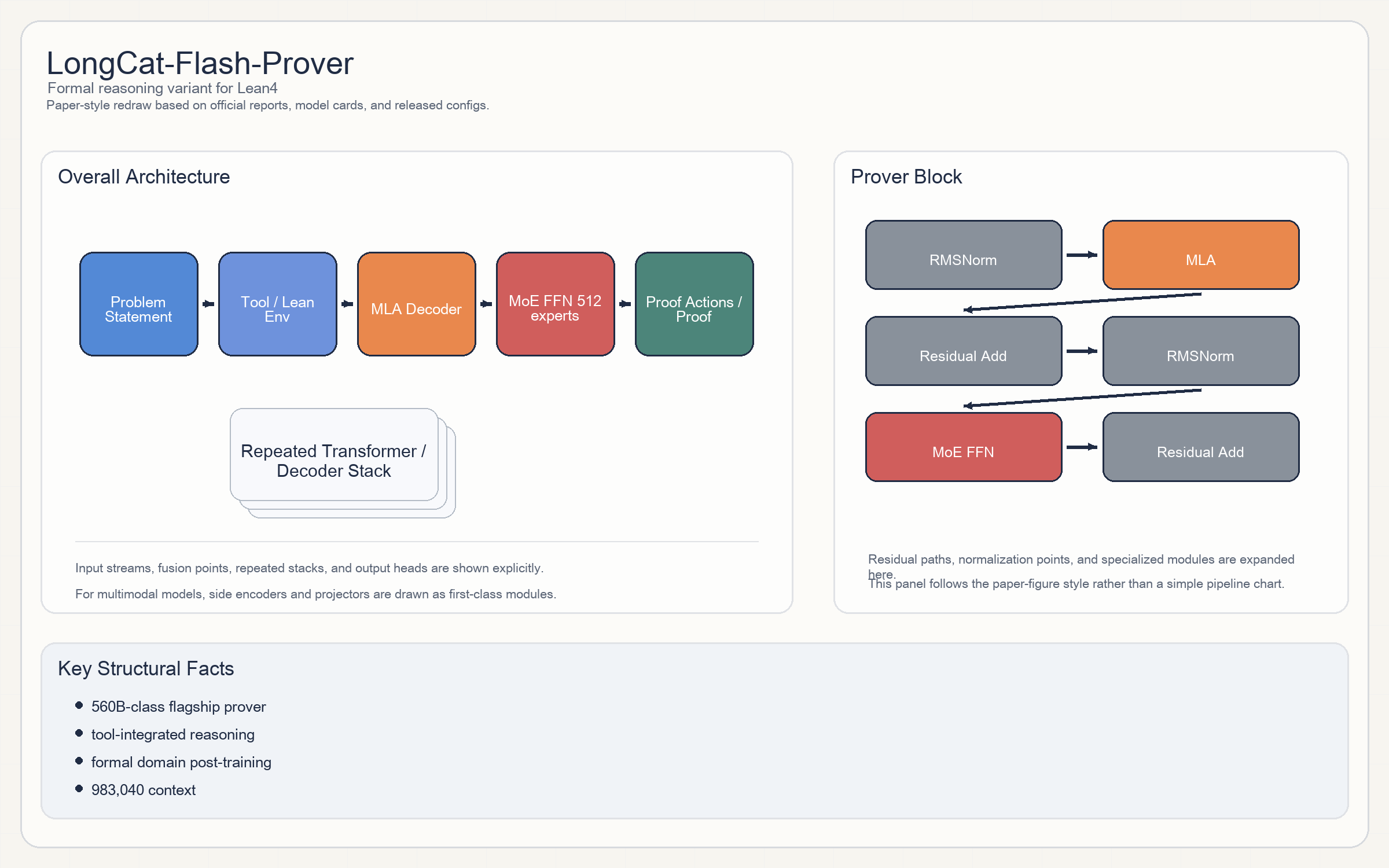
Release & Open Sources
- 发布时间:
2026-03-20。 - 形态:面向
Lean4和 formal reasoning 的专用 open-source MoE 模型。
Architecture
- 从 config 看,主干和
LongCat-Flash-Thinking-2601非常接近:MLA + massive MoE + top-12 routing + long context。 - 区别主要不在 block 结构,而在后训练目标、工具集成方式和证明环境适配。
- 因此它最适合被理解为一个“同主干、不同 RL / tool-use specialization”的推理变体。
Parameters & Hyperparameters
- 官方 README 直接给出
560B级 MoE。 - config 与 Flash-Thinking 近似:
6144 hidden、64 heads、512 experts、983,040context。
Training
- 技术报告
arXiv:2603.21065重点在 formal proving 的tool-integrated reasoning。 - 官方公开材料没有把 pretraining 数据重新拆出,而是把重点放在 proving domain 的 post-training 和 agent scaffolding。
Key Takeaways
- Flash-Prover 说明 2026 Q1 的一个明显趋势:开源厂商开始把“同一大主干 + 不同专业化后训练”做成独立 release,而不是只发布通用聊天模型。
Links
- 技术报告:arXiv:2603.21065
- 模型页:meituan-longcat/LongCat-Flash-Prover
- 仓库:meituan-longcat/LongCat-Flash-Prover
MiniMax
MiniMax-M2.5
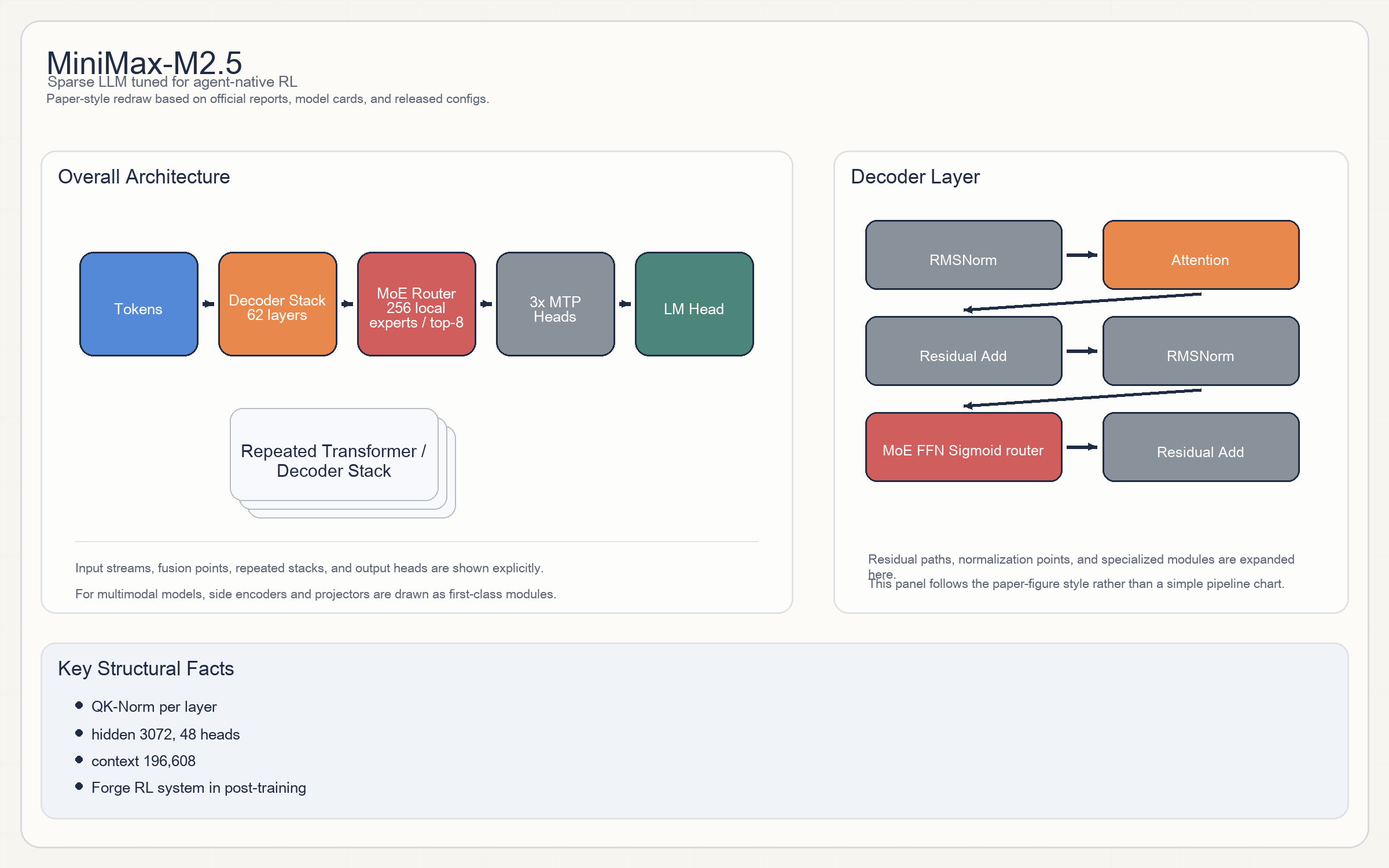
Release & Open Sources
- 发布时间:
2026-02-12。 - 官方来源:官网发布文、Forge RL 博客、GitHub、Hugging Face。
Architecture
MiniMax-M2.5是典型的 decoder-only sparse model。整体结构是token embedding -> 62 transformer layers -> 3 MTP modules -> LM head。- 单层 block 为
RMSNorm -> attention -> Residual -> RMSNorm -> MoE FFN -> Residual。 - config 公开了几项很关键的细节:
qk_norm_type = per_layer、routing scoring 使用sigmoid、支持MTP、3个MTP模块。 - Expert 路由是
256 local experts、每 token 激活8个专家;激活函数SiLU。 - 官方 blog 没有像一些论文那样细讲 attention 变体,但从 config 看它不是传统 dense transformer 的简单放大,而是明显围绕高吞吐 inference 和 RL rollout 做过结构优化。
Parameters & Hyperparameters
- config 可确认:
62 layers / 3072 hidden / 48 heads / 8 KV heads。 256 experts / top-8。- context
196,608。 rope_theta = 5e6,rotary_dim = 64,带QK-Norm与MTP。- 总参数和激活参数官方发布文没有在 README 顶部明确写出,公开材料更强调 RL 和成本,而非总参数营销。
Training
- 官方 blog 明确说 M2.5 在
hundreds of thousands of complex real-world environments上做了大规模 RL。 - 次日公开的
Forge博客补充了训练系统:最长200kcontext、日吞吐millions of samples、支持上万级 agent scaffold / environment 变化。 - 预训练数据量官方未在公开页面单独披露。
Key Takeaways
- M2.5 的公开重点不在“block 发明”本身,而在
MTP + sparse backbone + large-scale agent-native RL infrastructure的组合,这也是它和很多仅做指令微调的开源模型最不一样的地方。
Links
- 博客:MiniMax M2.5
- RL 博客:Forge: Scalable Agent RL Framework and Algorithm
- 官方仓库:MiniMax-AI/MiniMax-M2.5
- 模型页:MiniMaxAI/MiniMax-M2.5
Qwen / 通义千问
Qwen3-Coder-Next
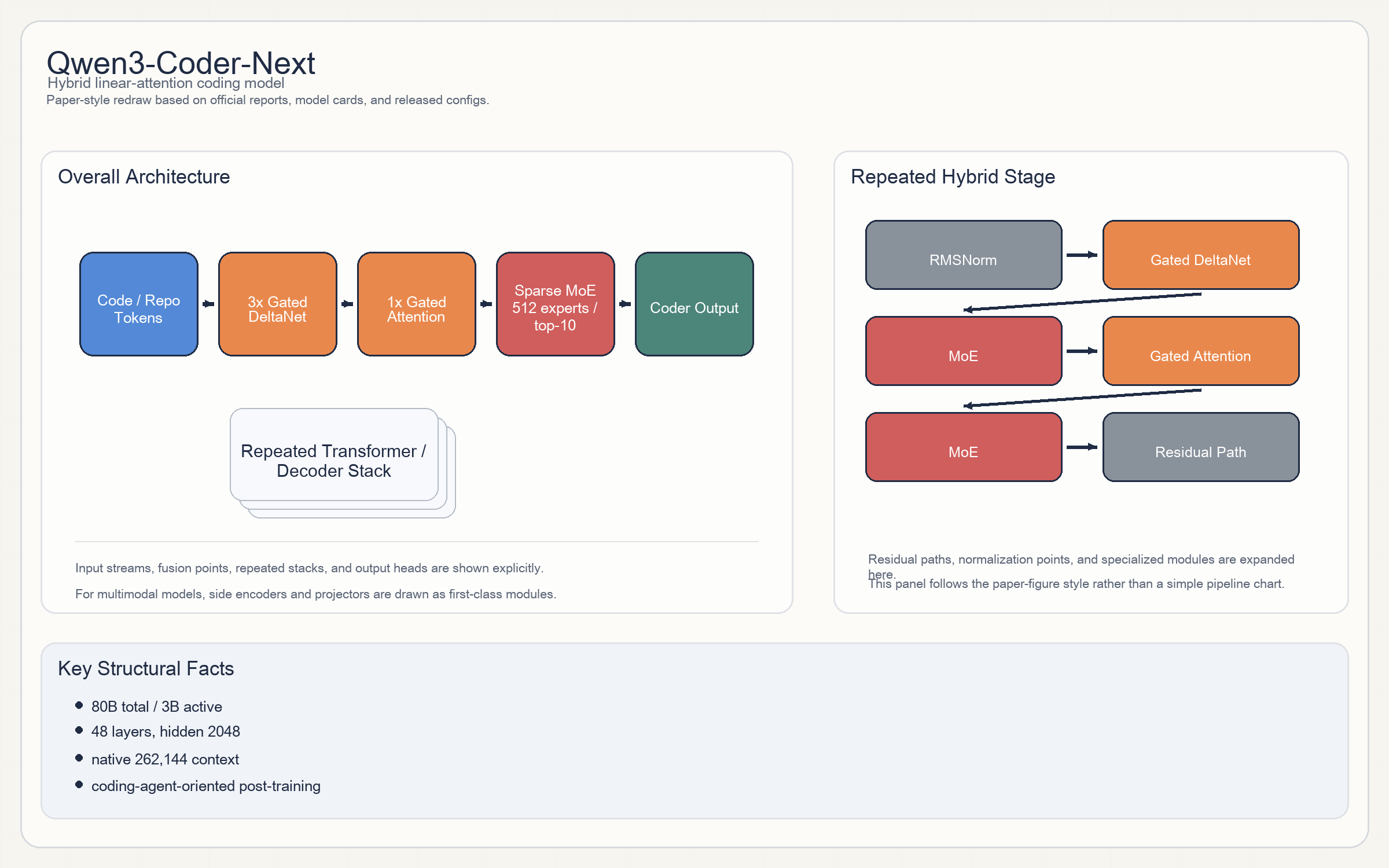
Release & Open Sources
- 发布时间:
2026-01-30。 - 形态:面向 coding agent 的专门模型。
Architecture
- 这不是普通 transformer 微调版,而是 Qwen 在 2026 Q1 最有辨识度的一条新结构线。
- 官方模型卡把隐藏布局直接写出来了:
12 × (3 × (Gated DeltaNet -> MoE) -> 1 × (Gated Attention -> MoE))。 - 换句话说,它把
linear attention / DeltaNet作为主路,由周期性Gated Attention补足全局建模;每个子层后面接稀疏 expert,而不是普通 dense MLP。 - Expert 路由:
512 experts、每 token 激活10个,另有1个 shared expert;激活函数SiLU。 - 这是 2026 Q1 开源模型里把 “混合线性注意力 + MoE” 讲得最清楚的一条。
Parameters & Hyperparameters
80B total / 3B activated。48 layers / 2048 hidden。16 Q heads / 2 KV heads。262,144native context。head_dim = 256,partial_rotary_factor = 0.25。
Training
- 官方模型卡把训练阶段写成
Pretraining & Post-training,并强调 long-horizon reasoning、tool use、failure recovery。 - 公开材料没有像 MiMo 那样给出完整 token 数,但明确定位于 coding agent 与本地 IDE / CLI 集成。
Key Takeaways
- Qwen3-Coder-Next 是 2026 Q1 最值得单独看 block 结构的开源代码模型之一,因为它不是传统 full-attention transformer 的简单增量版。
Links
- 博客:Qwen3-Coder-Next
- 技术报告:qwen3_coder_next_tech_report.pdf
- 官方仓库:QwenLM/Qwen3-Coder
- 模型页:Qwen/Qwen3-Coder-Next
Qwen3.5 Dense Family
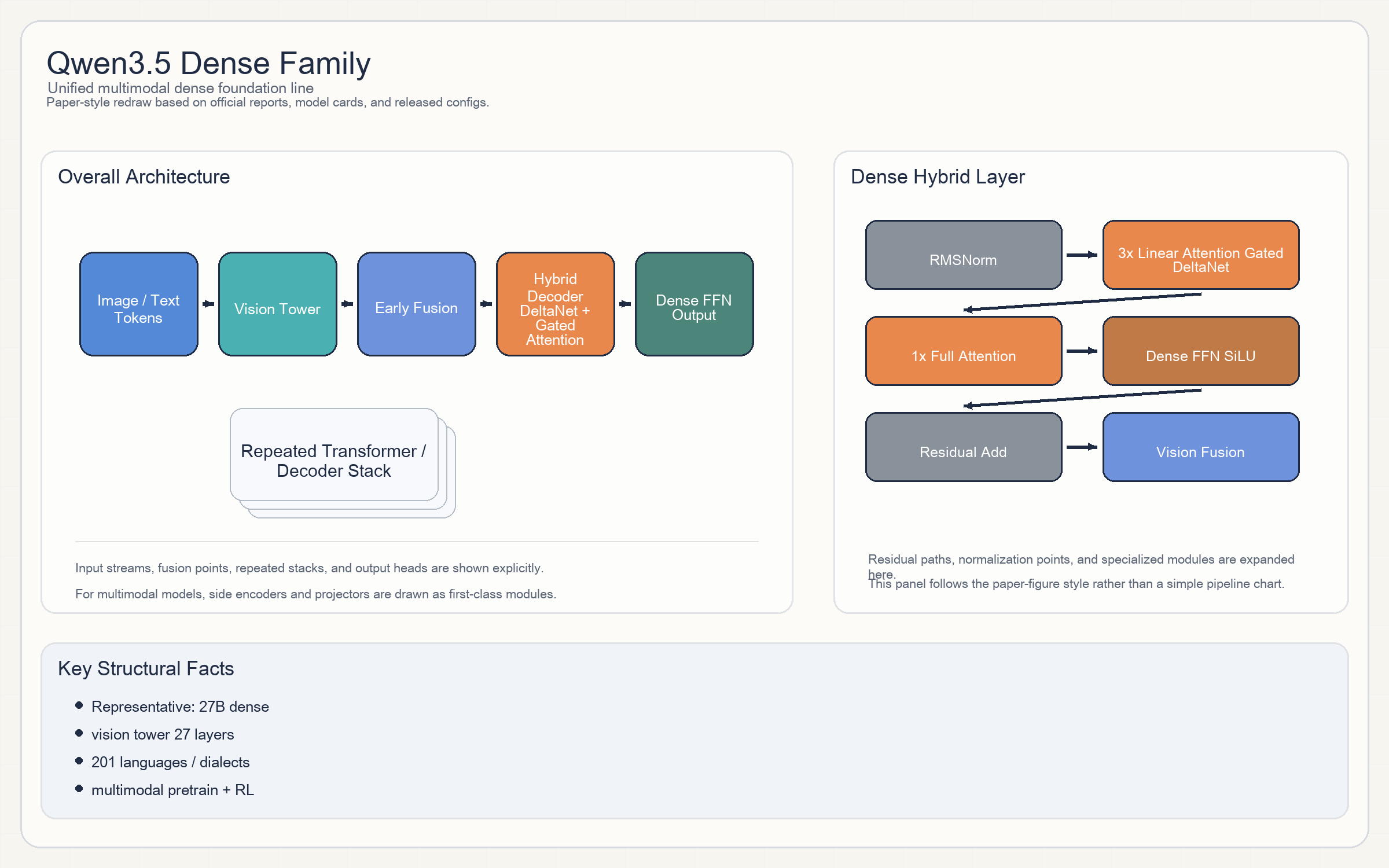
Release & Open Sources
- 发布时间:
2026-02-24起分批公开。 - 代表 checkpoint:
0.8B / 2B / 4B / 9B / 27B。
Architecture
- Qwen3.5 虽然官方定位是统一 foundation model,但在结构上已经和传统 “纯 full attention + FFN” 相当不同。
- Dense 线的隐藏布局由官方直接公开:以
27B为例,16 × (3 × (Gated DeltaNet -> FFN) -> 1 × (Gated Attention -> FFN))。 - 因此它的主 block 不是“每层都 full attention”,而是
3 个 linear / DeltaNet 层 + 1 个 gated full attention 层的周期结构。 - 这条线同时已经是原生
vision-language:视觉塔与文本主干在统一 token 空间里做 early fusion。 - 激活函数
SiLU,visual tower 的激活为gelu_pytorch_tanh。
Parameters & Hyperparameters
- 以
27B为例:64 layers / 5120 hidden / 24 Q heads / 4 KV heads。 - dense FFN intermediate:
17408。 - context:原生
262,144,官方 blog 标注可扩到约1.01M。 - 视觉塔:
27层、1152 hidden、patch 16。
Training
- 官方明确写出是
Pre-training & Post-training。 - 重点不再只是语言数据,而是
Early fusion multimodal tokens + million-agent RL infrastructure + 201 languages and dialects。 - 具体 token 数官方 release 未披露。
Key Takeaways
- Qwen3.5 Dense 的意义在于:阿里把
hybrid linear/full attention、native multimodal fusion和大规模 agent RL 合并进了通用 foundation model 主线。
Links
- 博客:Qwen3.5
- 模型页:Qwen/Qwen3.5-27B
- 组织页:Qwen on Hugging Face
Qwen3.5 MoE Family
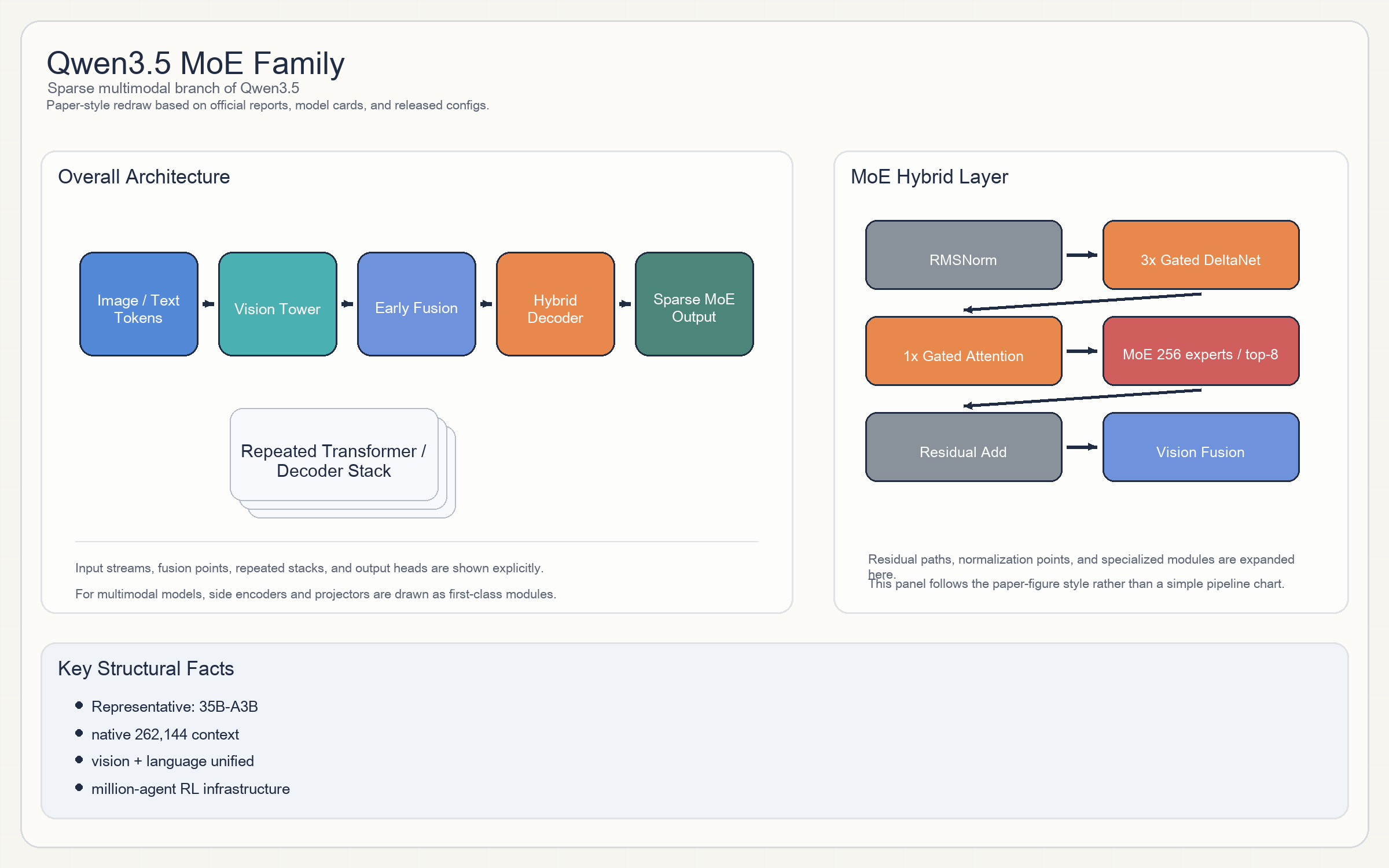
Release & Open Sources
- 发布时间:
2026-02-24起分批公开。 - 代表 checkpoint:
35B-A3B / 122B-A10B / 397B-A17B。
Architecture
- MoE 线延续 Qwen3.5 的
3 × Gated DeltaNet + 1 × Gated Attention周期结构,但 FFN 被稀疏 experts 替代。 - 以
35B-A3B为例,官方写的是10 × (3 × (Gated DeltaNet -> MoE) -> 1 × (Gated Attention -> MoE))。 - config 可确认:
256 experts、每 token 激活8个;视觉塔与 dense 线共用同一代视觉 backbone。 - 这让 Qwen3.5 MoE 既保留 hybrid attention 的效率,又把激活参数压低到更适合部署的范围。
Parameters & Hyperparameters
35B total / 3B active是最容易本地部署的代表。- 其 config:
40 layers / 2048 hidden / 16 Q heads / 2 KV heads / 256 experts / top-8。 - context 同样是
262,144原生。
Training
- 与 Dense 线同属
Qwen3.5统一 recipe:multimodal pretraining + large-scale RL + multilingual expansion。 - 公开 release 没把各尺寸 token 预算拆开。
Key Takeaways
- Qwen3.5 MoE 更像是“把 Qwen3-Coder-Next 那套 hybrid sparse 思路推向通用 foundation model”,而不是简单做一个 MoE 版 Qwen。
Links
- 博客:Qwen3.5
- 模型页:Qwen/Qwen3.5-35B-A3B
- 组织页:Qwen on Hugging Face
Z.ai / 智谱
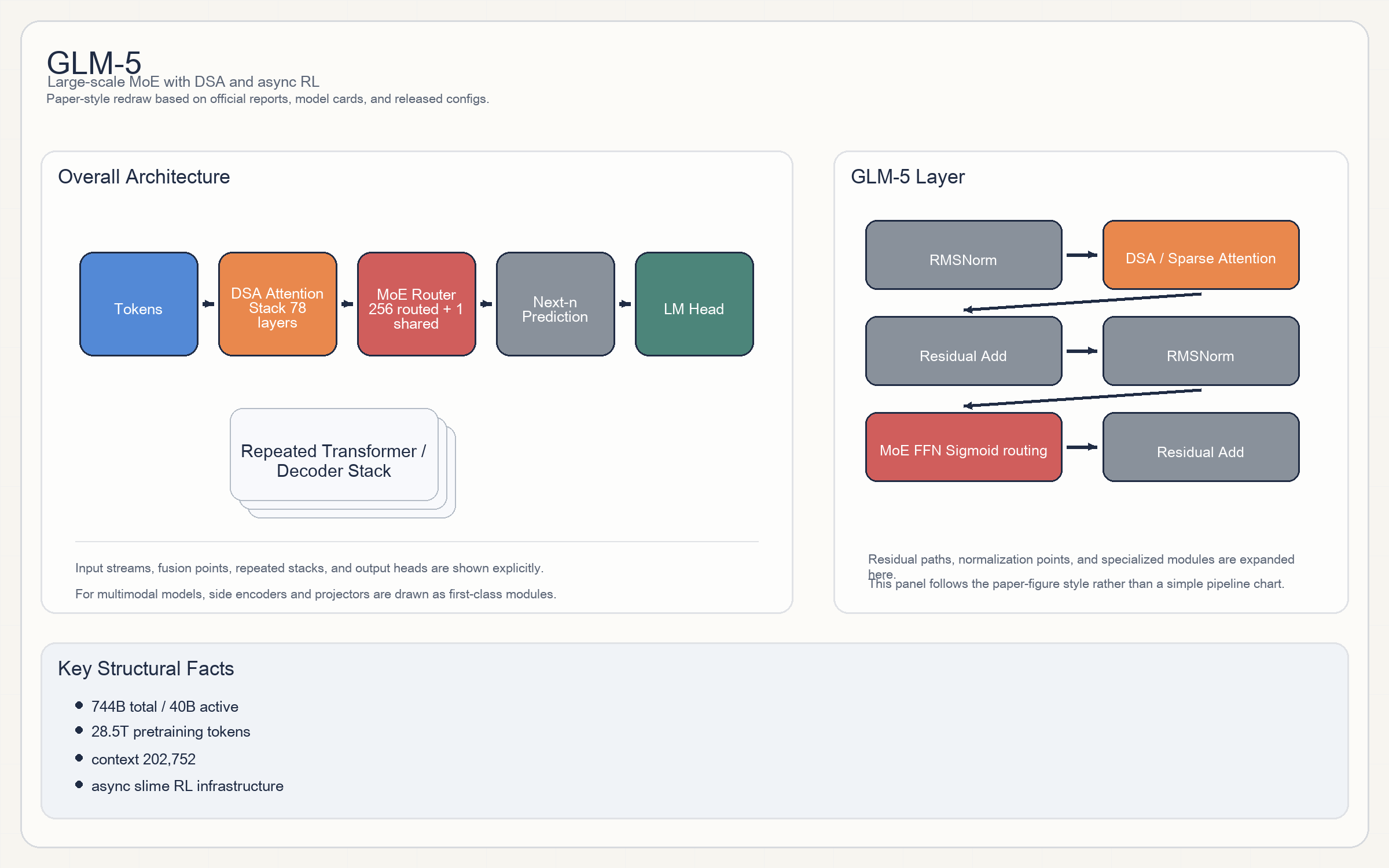
GLM-5
Release & Open Sources
- 发布时间:
2026-02-11。 - 官方来源:技术博客、paper、GitHub、Hugging Face。
Architecture
GLM-5是典型的超大MoELLM,但它的关键创新点不是“多几个 experts”,而是把DSA(DeepSeek Sparse Attention)也整合进来了。- 每个 block 可概括为:
RMSNorm -> DSA/attention -> Residual -> RMSNorm -> MoE FFN -> Residual。 - config 明确出现了
model_type = glm_moe_dsa、num_nextn_predict_layers = 1,说明它同时用了稀疏注意力和MTP/next-token draft。 - Expert routing:
256 routed experts + 1 shared expert,每 token 激活8个,routing 使用sigmoid风格 noaux top-k。
Parameters & Hyperparameters
- 官方博客给出:从
GLM-4.7的355B (32B active)扩到744B (40B active)。 - config:
78 layers / 6144 hidden / 64 heads / 256 experts / top-8 / 202,752 context。 - 另外有
q_lora_rank = 2048、kv_lora_rank = 512、qk_head_dim = 256、rope_theta = 1e6。
Training
- 预训练:官方 blog 明确写了从
23T增加到28.5T tokens。 - 后训练:重点在大规模 RL,且官方直接把训练基础设施
slime开源出来,强调 asynchronous RL 提高吞吐与迭代速度。
Key Takeaways
- GLM-5 的价值在于它把
超大 MoE + sparse attention + async RL infra + long-horizon agent tasks这几条线一起推到了新的开源上限。
Links
- 博客:GLM-5 Technical Blog
- 技术报告:arXiv:2602.15763
- 官方仓库:zai-org/GLM-5
- 模型页:zai-org/GLM-5
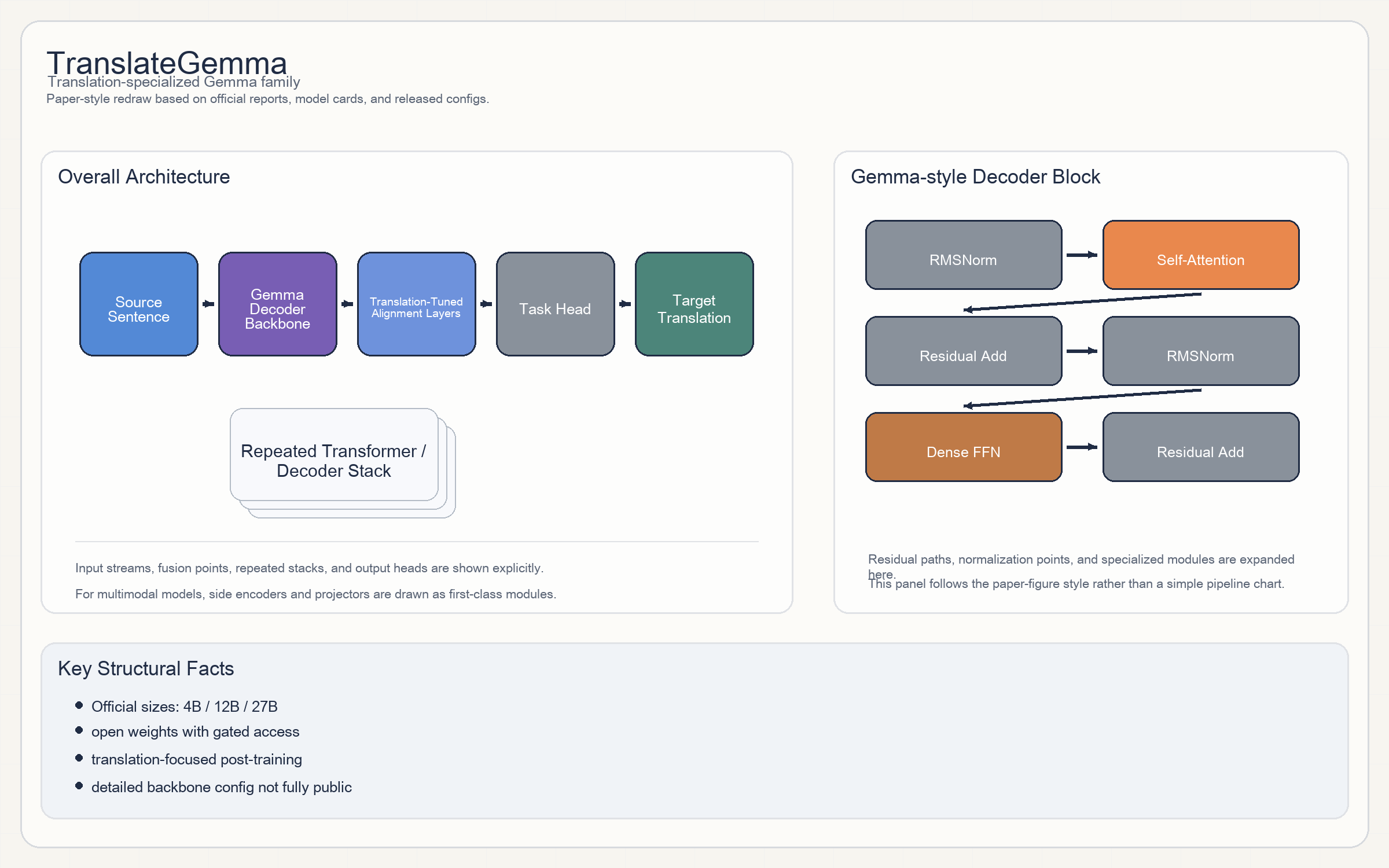
TranslateGemma
Release & Open Sources
- 发布时间:
2026-01-12。 - 家族尺寸:
4B / 12B / 27B。 - 这是官方开放权重但 gated access 的发布。
Architecture
TranslateGemma的 2026 release 不是一条全新 backbone,而是在Gemma主干上做专门的 translation post-training。- 因此 block 结构基本继承 Gemma decoder 架构;
TranslateGemma本次 release 主要公开的是任务目标和训练 recipe,而不是重新定义 attention / MLP block。 - 从官方文档能确认的是:这是 text-only translation family,不是独立的 multimodal backbone。
- 逐层 hidden size / heads / activation 在 gated 文档外没有像其他模型卡那样完全公开,所以这里不做无来源补写。
Parameters & Hyperparameters
- 公开确认的家族尺寸:
4B / 12B / 27B。 - 更细的逐层 config 依赖 gated 模型页;公开 blog / paper 没有完整重复。
Training
- 官方论文把重点放在高质量翻译的 teacher-student / RL / reward 建模 recipe,而不是 backbone 变化。
- 公开 release 强调 instruction-tuned translation、对多语种和高资源 / 低资源场景的泛化。
Key Takeaways
- TranslateGemma 代表的是 2026 Q1 一个很值得注意的方向:大型开源厂商不只发“通用聊天模型”,也开始发有明确应用目标的专门家族。
Links
- 技术报告:TranslateGemma Technical Report
- 模型页:google/translategemma-4b-it
- 模型页:google/translategemma-12b-it
- 模型页:google/translategemma-27b-it
Mistral AI
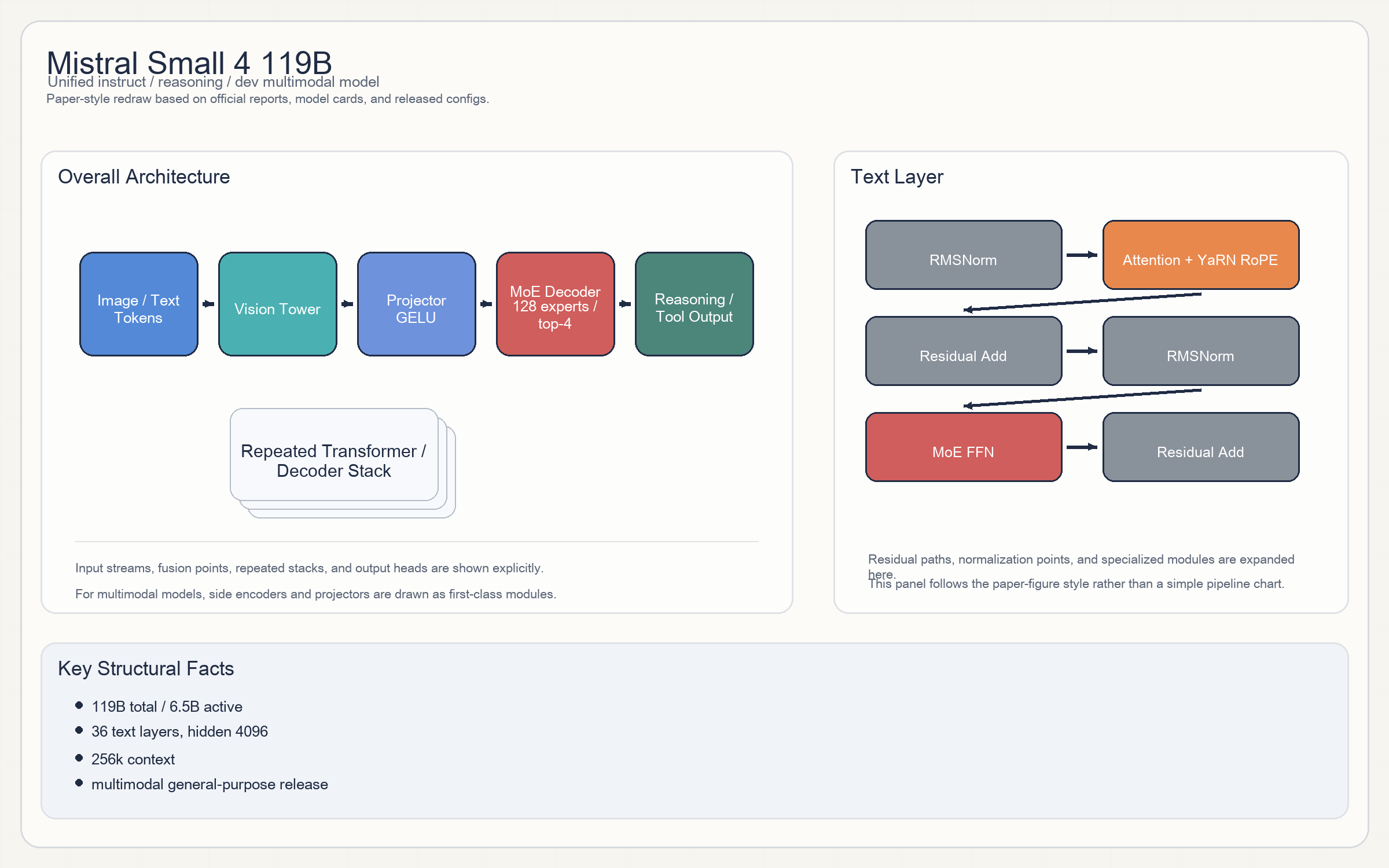
Mistral Small 4 119B
Release & Open Sources
- 发布时间:
2026-01-23。 - 形态:Mistral 把它定位成统一的 general / reasoning / dev model。
Architecture
- 主干是一个多模态
MoE模型:vision tower + projector + MoE text decoder。 - 单个文本 block 仍是标准 pre-norm decoder 结构,但 attention 侧已经使用
q_lora_rank/kv_lora_rank风格参数化,并在 rope 上用了YaRN扩展。 - Experts:
128 routed experts + 1 shared expert,每 token 激活4个;激活函数SiLU。 - multimodal projector 使用
GELU,说明视觉连接器与文本主干在非线性上是分开的。
Parameters & Hyperparameters
119B total / 6.5B active。36 layers / 4096 hidden / 32 heads / 32 KV heads。256kcontext。- vision tower:
1024 hidden、patch 14。
Training
- 官方卡片强调这是一条 unified family,把 instruct、reasoning、devstral 三条线并起来。
- 公开页面更突出多模态、reasoning mode、tool use,对 pretraining token 数没有单独披露。
Key Takeaways
- Mistral Small 4 的要点在“统一工作模式”,不是单点 benchmark;它明显是在做一个既能快答也能切 reasoning mode 的工作模型。
Links
StepFun / 阶跃星辰
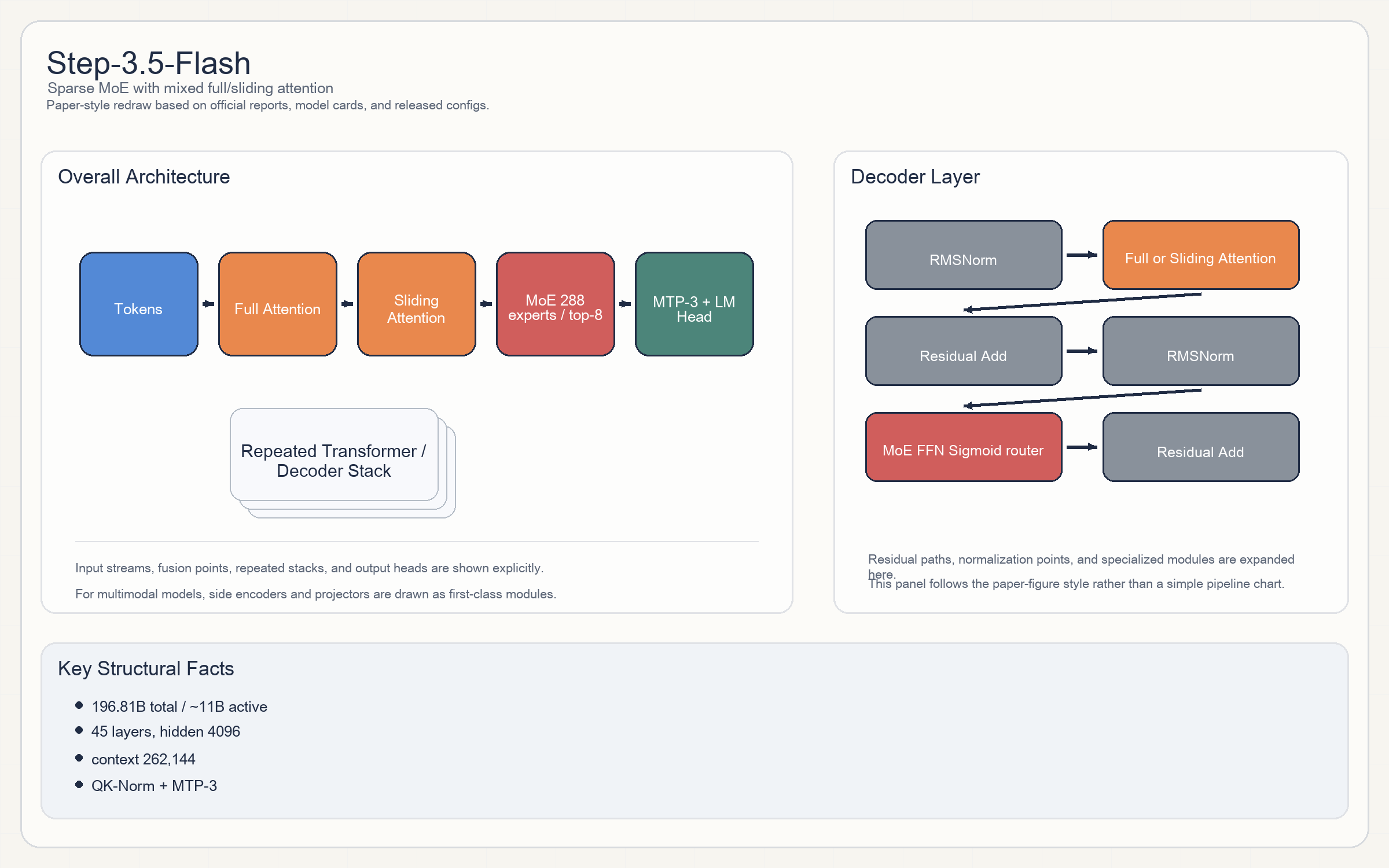
Step-3.5-Flash
Release & Open Sources
- 发布时间:
2026-02-01。 - 官方来源:blog、arXiv、GitHub、HF、ModelScope。
Architecture
Step-3.5-Flash是一条典型的高效率MoELLM,但 attention 排布并不简单。- 主体仍是 decoder-only。根据 config,它交替使用
full_attention与sliding_attention,sliding window 为512。 - 每层 block 结构可以写成:
Norm -> Attention(full/sliding, with QK-Norm) -> Residual -> Norm -> MoE -> Residual。 - Experts:
288 experts、每 tokentop-8、router 激活是sigmoid,还有shared expert。 - 官方还明确把
MTP-3作为 recipe 核心之一。
Parameters & Hyperparameters
- 官方给出
196.81B total / ~11B active。 45 layers / 4096 hidden / 64 heads。262,144context。rope采用分层组合值,说明 attention pattern 和 position encoding 是联动设计的。
Training
- 官方文档强调 frontier reasoning、agentic capabilities 与后续会继续开源 SFT / RL 代码。
- 公开页面没有像 GLM-5 那样给出完整预训练 token 数。
Key Takeaways
- Step-3.5-Flash 最值得注意的是它的“部署友好型大 MoE”思路:
mixed attention pattern + QK norm + MTP-3 + top-8 routing。
Links
- 博客:Step 3.5 Flash
- 技术报告:arXiv:2602.10604
- 官方仓库:stepfun-ai/Step-3.5-Flash
- 模型页:stepfun-ai/Step-3.5-Flash
NVIDIA
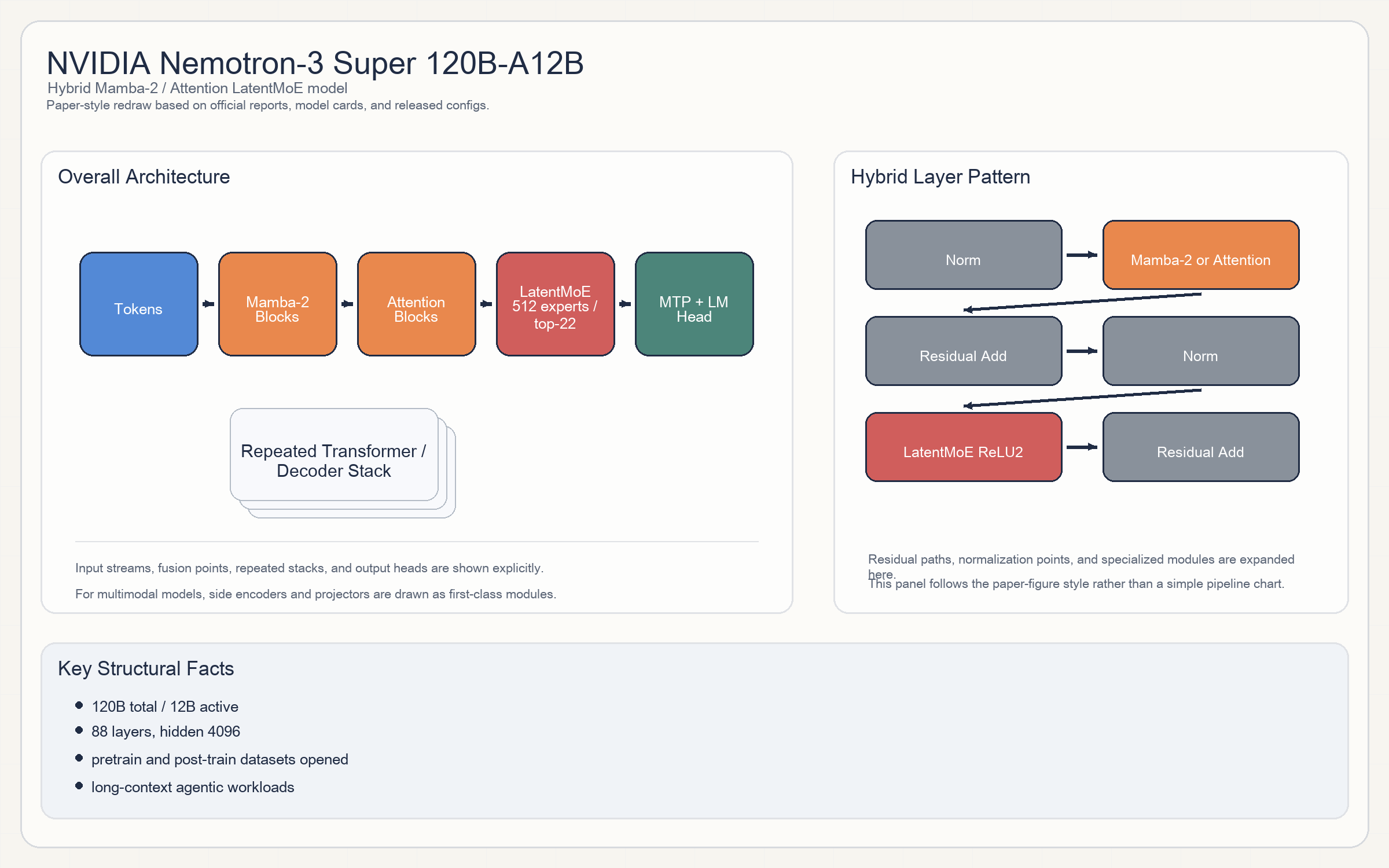
NVIDIA Nemotron-3 Super 120B-A12B
Release & Open Sources
- 发布时间:
2026-03-10。 - 形态:NVIDIA 自己明确写成
LatentMoE - Mamba-2 + MoE + Attention hybrid with MTP。
Architecture
- 这是本文里结构最异质的一条 LLM 之一。它不是“纯 transformer”,而是
Mamba-2 / state-space + attention + latent MoE的混合主干。 - config 中的
hybrid_override_pattern与mtp_hybrid_override_pattern说明主干在不同层交替使用Mamba和Attention,并在末端加MTP。 - block 粗略上可写成:
Norm -> (Mamba or Attention) -> Residual -> Norm -> LatentMoE -> Residual。 - MLP 激活不是最常见的
SiLU/SwiGLU,而是公开成了relu2,这是它很少见的一点。 - Experts:
512 routed experts + 1 shared expert,每 token 激活22个。
Parameters & Hyperparameters
120B total / 12B active。88 layers / 4096 hidden / 32 heads / 2 KV heads。262,144context;官方页写可扩到1M级工作场景。- 其他关键值:
conv_kernel = 4、chunk_size = 128、moe_latent_size = 1024。
Training
- 官方同时公开了
pre-training datasets与post-training datasetscollection。 - README 说明:pretraining 数据截止
2025-06,post-training 数据截止2026-02。
Key Takeaways
- Nemotron-3 Super 的意义在于它把 2026 年流行的几条效率线几乎全揉在一起了:
SSM + Attention hybrid + LatentMoE + MTP + open datasets。
Links
- 技术报告:NVIDIA Nemotron-3 Super Technical Report
- 模型页:nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-BF16
- 开发者页:NVIDIA Nemotron
VLM
MedGemma 1.5 4B
Release & Open Sources
- 发布时间:
2026-01-07。 - 形态:医疗场景视觉语言模型,官方开放权重但 gated access。
Architecture
- MedGemma 不是全新 backbone,而是沿用 Gemma / 医疗视觉家族的通用视觉语言框架:
medical image encoder + Gemma text decoder + multimodal projector。 - 公开 release 的重点是 domain adaptation,而不是发明新的 attention block。
- 因为官方 gated 页面之外没有公开完整 config,本节只写官方确认的结构层级,不猜逐层超参数。
Parameters & Hyperparameters
- 家族公开尺寸中,本轮常用公开 checkpoint 为
4B。 - 更细的 hidden size / heads / FFN 宽度在公开页面未完全披露。
Training
- 官方文档强调医疗图像与临床问答场景的适配。
- 公开 release 更强调 domain post-training 与安全评估,不像一般基础模型那样披露完整 token 预算。
Key Takeaways
- MedGemma 的意义在“医疗 domain 开放模型家族”,不是架构大改。
Links
- 模型页:google/medgemma-1.5-4b-it
- Google 开源模型页:google on Hugging Face
- 技术报告:MedGemma Technical Report
StepFun / 阶跃星辰
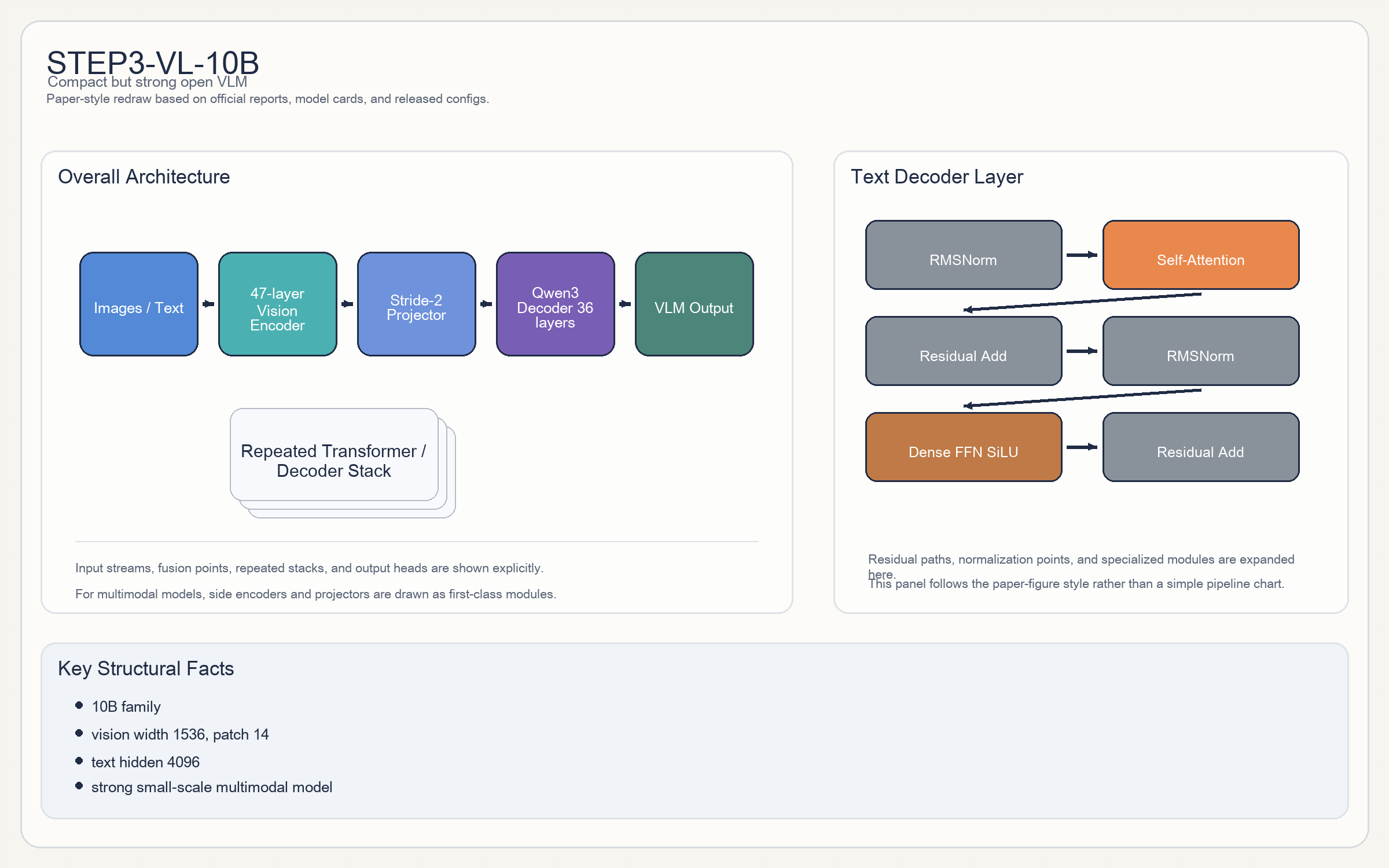
Step3-VL-10B
Release & Open Sources
- 发布时间:
2026-01-13。 - 官方来源:paper、HF、ModelScope、GitHub 组织。
Architecture
- 整体结构是
vision encoder + projector + Qwen3-based text decoder。 - 视觉塔很大:
47层、1536width、patch 14、image_size 728,激活函数quick_gelu。 - 文本侧是
Qwen3风格 decoder:36 layers,block 为RMSNorm -> attention -> residual -> RMSNorm -> MLP -> residual,激活函数SiLU。 - projector stride
2,说明它通过下采样控制视觉 token 数,而不是简单暴力拼接。
Parameters & Hyperparameters
- 官方定位是
10B量级。 - 文本侧 config:
4096 hidden / 36 layers / 32 heads / 8 KV heads / 65536 context。 - 视觉侧:
47 layers / width 1536 / patch 14 / image size 728。
Training
- 技术报告
arXiv:2601.09668。 - 官方 release 强调“10B 尺度下的前沿级多模态能力”,重点在视觉理解、推理和 alignment。
- 公开页面没有完整披露 multimodal pretraining 数据量。
Key Takeaways
- Step3-VL-10B 的重要性在于:它不是把小视觉模型挂在小 LLM 上,而是非常认真地给 10B 量级做了一套大视觉塔 + 强文本主干的配比。
Links
Z.ai / 智谱
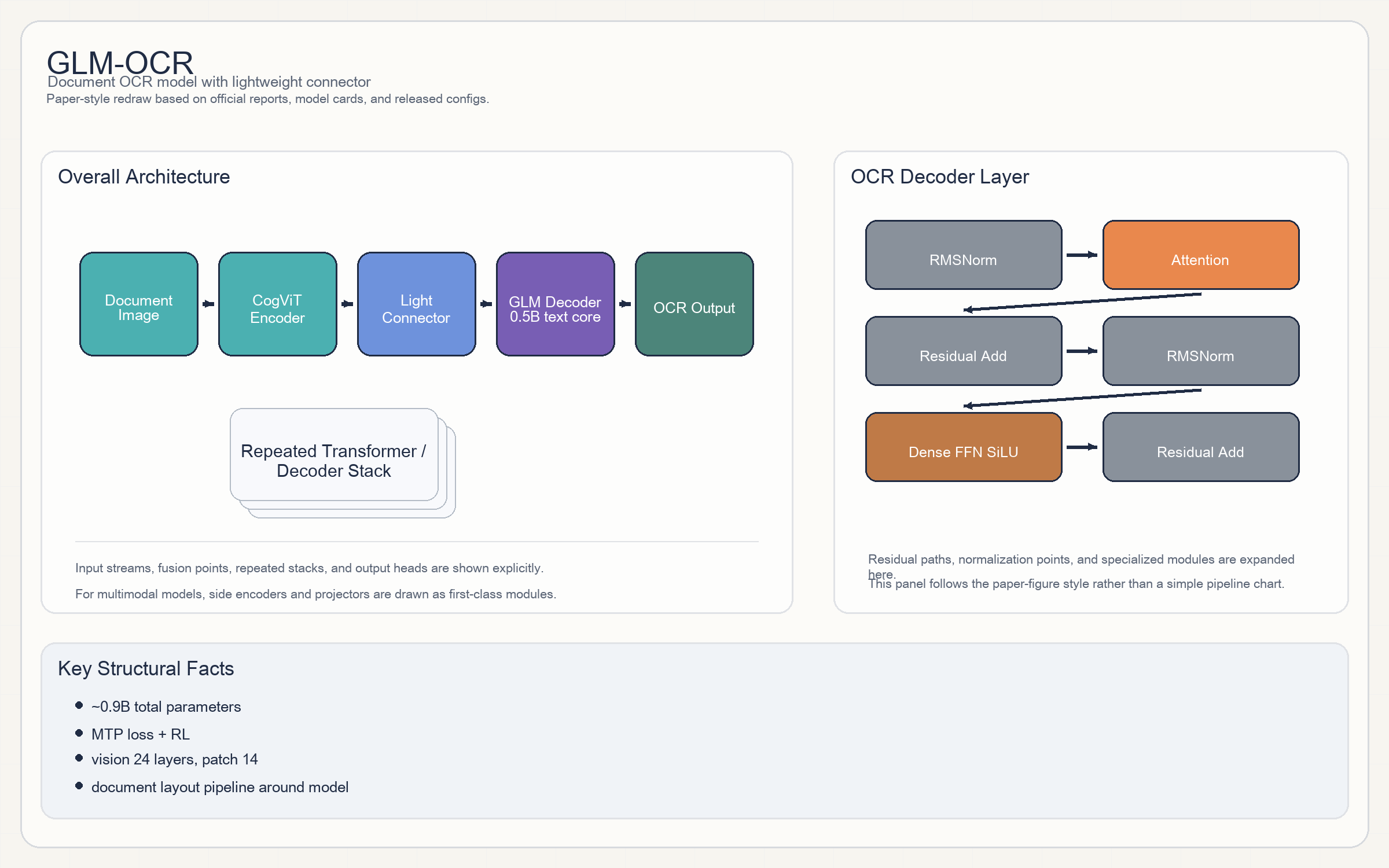
GLM-OCR
Release & Open Sources
- 发布时间:
2026-01-30。 - 形态:复杂文档 OCR / document understanding 模型。
Architecture
- 这是一个非常清晰的
vision encoder + lightweight connector + text decoder结构。 - 官方 README 直接写出:视觉侧基于
CogViT,文本侧是GLM-0.5B decoder,同时引入MTP loss和 full-task RL。 - 从 config 看,视觉塔
24层、1024 hidden、patch 14、输出到1536维;文本 decoder 为16 layers / 1536 hidden / 16 heads / 8 KV heads。 - block 层级上,视觉和文本两侧激活函数都使用
SiLU。
Parameters & Hyperparameters
- 官方给出整模型约
0.9B。 - 文本侧 context
131072。 - 视觉侧 image size
336,spatial_merge_size = 2。 - 文本侧还有
num_nextn_predict_layers = 1,说明它也在做 next-token draft / MTP。
Training
- 官方重点披露的是两阶段系统:布局分析依赖
PP-DocLayout-V3,识别模型再做并行识别。 - 训练方法包括
MTP loss与稳定 RL;完整数据量未在 README 顶部披露。
Key Takeaways
- GLM-OCR 很像一个面向工业文档场景打磨过的 VLM,而不是单纯把聊天 VLM 拿来做 OCR。
Links
- 技术报告:arXiv:2603.10910
- 官方仓库:zai-org/GLM-OCR
- 模型页:zai-org/GLM-OCR
DeepSeek
DeepSeek-OCR-2

Release & Open Sources
- 发布时间:
2026-01-27。 - 形态:视觉因果流 OCR 模型。
Architecture
- 这条线不是标准的“视觉塔 + 大 decoder”复制,而是明显针对 OCR 任务做过裁剪。
- 视觉侧融合了
SAM ViT-B与DeepEncoderV2风格模块,之后接线性 projector,再接一个DeepSeekV2风格语言侧。 - 文本主干:
12 layers / 1280 hidden / 10 heads / 64 experts / top-6。 - projector 非常轻:
linear projector,把视觉表征投到1280维文本空间。
Parameters & Hyperparameters
- 语言侧:
1280 hidden / 12 layers / 10 heads / 10 KV heads / 8192 context。 - experts:
64 routed + 2 shared,top-6。 - 视觉分辨率:官方 config 支持
1024 x 1024candidate resolution。
Training
- 技术报告
arXiv:2601.20552。 - 官方强调 “visual causal flow”,说明它想解决的不是单页 OCR 精度而已,而是更接近人类阅读顺序的 causal visual encoding。
- README 没有完整披露预训练 / 后训练 token 数。
Key Takeaways
- DeepSeek-OCR-2 的方向很清晰:把 OCR 当成“视觉序列到文本序列”的因果建模问题,而不是传统检测+识别拼接。
Links
IBM
Granite 4.0 3B Vision
Release & Open Sources
- 发布时间:
2026-03-03。 - 形态:轻量视觉语言模型,偏 document / enterprise use case。
Architecture
- 总体结构是
vision encoder + projector + Granite 4.0 text backbone。 - 文本主干
40 layers / 2560 hidden / 40 heads / 8 KV heads;激活SiLU。 - 视觉塔
1152 hidden / patch 16 / image size 384。 - README 提到
Deepstack injection:视觉特征在多个层位点加性注入文本隐藏状态,而不是只做单次前置拼接。这是它比较有辨识度的一点。
Parameters & Hyperparameters
- 官方模型名给出
3B级。 - 文本侧 context
131072。 - projector 激活
GELU。 - 公开页面没有把总激活参数拆成 dense / sparse 两部分。
Training
- README 强调文档解析、图表、表格与结构化提取场景。
- 训练数据里至少明确出现了
ChartNet和 Granite Vision instruction-following 数据。
Key Takeaways
- Granite 4.0 3B Vision 更像一条 enterprise document VLM,而不是追求通用多模态 benchmark 排名的消费级模型。
Links
- 模型页:ibm-granite/granite-4.0-3b-vision
- IBM Granite 门户:IBM Granite
- GitHub 组织页:ibm-granite
Other Multimodal
Meituan / 美团
LongCat-Next
Release & Open Sources
- 发布时间:
2026-03-25。 - 形态:原生离散多模态模型,支持 text / image / audio。
Architecture
LongCat-Next是本文里最像“native multimodal stack”的国内模型之一。- 文本主干沿用 LongCat 稀疏主线:
3072 hidden / 32 heads / 256 experts / top-12。 - 视觉侧官方突出
dNaViT(Discrete Native-Resolution Vision Transformer),说明它不是简单把图像 resize 后切 patch,而是为 native-resolution 离散视觉 token 设计的视觉前端。 - config 里还能看到音频相关字段、VQ 配置和视觉 embedding 层,说明它把视觉 / 音频离散 token 直接纳入统一生成框架。
Parameters & Hyperparameters
- 文本侧:
14 layers / 3072 hidden / 32 heads / 131072 context。 - 视觉 embedding 隐层:
8192intermediate。 - 词表:总词表
282624,说明大量多模态特殊 token 已经并入主词表。
Training
- 公开材料强调“native multimodality”与 tokenizers 一并开源。
- 完整训练数据量官方未披露。
Key Takeaways
- LongCat-Next 的关键不在于又做了一个聊天 VLM,而是在试图把 image/audio token 真正作为一等公民塞进统一生成框架。
Links
- 博客:LongCat-Next Intro
- 技术报告:LongCat-Next Tech Report
- 官方仓库:meituan-longcat/LongCat-Next
- 模型页:meituan-longcat/LongCat-Next
EvoCUA
Release & Open Sources
- 发布时间:
2026-01-05首发32B,2026-01-13首发8B。 - 形态:computer-use agent 模型。
Architecture
EvoCUA没有重新发明一套新的 VLM backbone,而是基于Qwen3-VL主干做 computer-use 强化。- 因此其模型 block 仍是
Qwen3-VL式vision tower + projector + decoder。真正新的部分在动作建模、任务环境和后训练。 - 从模型页可确认 base models 是
Qwen/Qwen3-VL-32B与对应小尺寸版本。
Parameters & Hyperparameters
- 开源版本:
32B与8B。 32B版 config:64 text layers / 5120 hidden / 64 heads / 8 KV heads / 262144 context。- 视觉塔:
27层、1152 hidden、patch 16。
Training
- 这是官方公开得最完整的一条 computer-use 训练线之一:
Cold Start -> RFT -> RL。 - 美团博客明确强调可验证数据合成引擎、十万级并发交互沙盒、以及从“静态轨迹模仿”转到“经验进化学习”。
Key Takeaways
- EvoCUA 不是“又一个 GUI agent demo”,而是把
computer-use environment + policy training + open checkpoints一起放了出来。
Links
- 博客:美团 EvoCUA 技术博客
- 技术报告:arXiv:2601.15876
- 模型页:meituan/EvoCUA-32B-20260105
- 模型页:meituan/EvoCUA-8B-20260105
LongCat-Image-Edit-Turbo
Release & Open Sources
- 发布时间:
2026-02-03。 - 说明:这是 2026 发布的 Turbo 变体,架构说明依赖家族官方技术报告。
Architecture
- 它是
LongCat-Image-Edit的蒸馏 turbo 版本,目标是把高质量图像编辑压到极低NFE。 - README 直接写明:Turbo 版在
8 NFE下完成高质量编辑,这说明底层仍然是扩散式编辑框架,只是蒸馏得更激进。 - 公开 config 很轻,未把 backbone 层级全部展开,因此 block 级细节主要来自家族报告而不是 Turbo config 文件。
Parameters & Hyperparameters
- Turbo 版公开页主要强调
8 NFE。 - 更细的层数、hidden size 没有在 Turbo 模型页完整披露。
Training
- 采用家族报告里的图像编辑 / 生成训练管线;Turbo 版是蒸馏加速。
- 基础报告首发于 2025 末,Turbo 变体在 2026 Q1 开放。
Key Takeaways
- 这条线的重要性在于把“高质量图像编辑”和“极低 NFE”同时做成了开源变体。
Links
- 技术报告:LongCat-Image Technical Report
- 官方仓库:meituan-longcat/LongCat-Image
- 模型页:meituan-longcat/LongCat-Image-Edit-Turbo
Z.ai / 智谱
GLM-Image
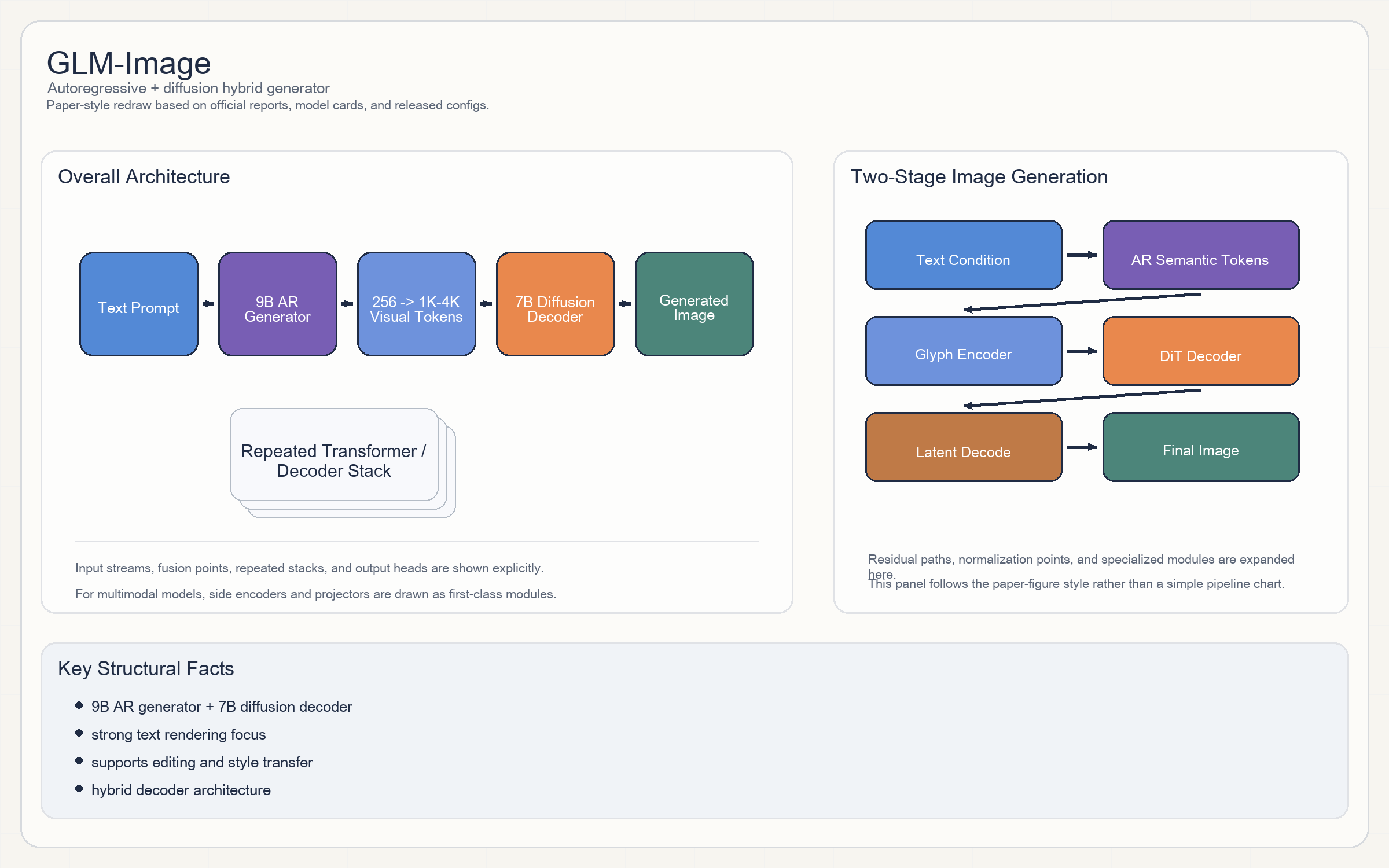
Release & Open Sources
- 发布时间:
2026-01-08。 - 形态:文本到图像 + 图像编辑模型。
Architecture
- 这条线非常值得单独看,因为它不是纯 diffusion,而是
autoregressive generator + diffusion decoder的双阶段混合结构。 - 官方 README 直接写了两部分:
9B autoregressive generator,先生成约256个紧凑视觉编码,再扩展到1K-4Ktoken;7B diffusion decoder,采用 single-streamDiT。
- 扩散解码器里还带
Glyph Encoder,这是它能把图像内文字渲染做得更好的关键。
Parameters & Hyperparameters
9B AR generator + 7B diffusion decoder。- AR 主干初始化自
GLM-4-9B-0414。 - 生成 token 范围:大约
256 -> 1K-4K视觉 token。
Training
- 官方博客强调它在 text rendering、知识密集型生成与 image editing 上的优势。
- 更细的训练数据量未在 README 顶部披露。
Key Takeaways
- GLM-Image 说明 2026 年国内开源图像模型已经不满足于“再做一个 latent diffusion”,而是在探索 AR 与 diffusion 的组合式解码。
Links
Qwen / 通义千问
Qwen3-ASR
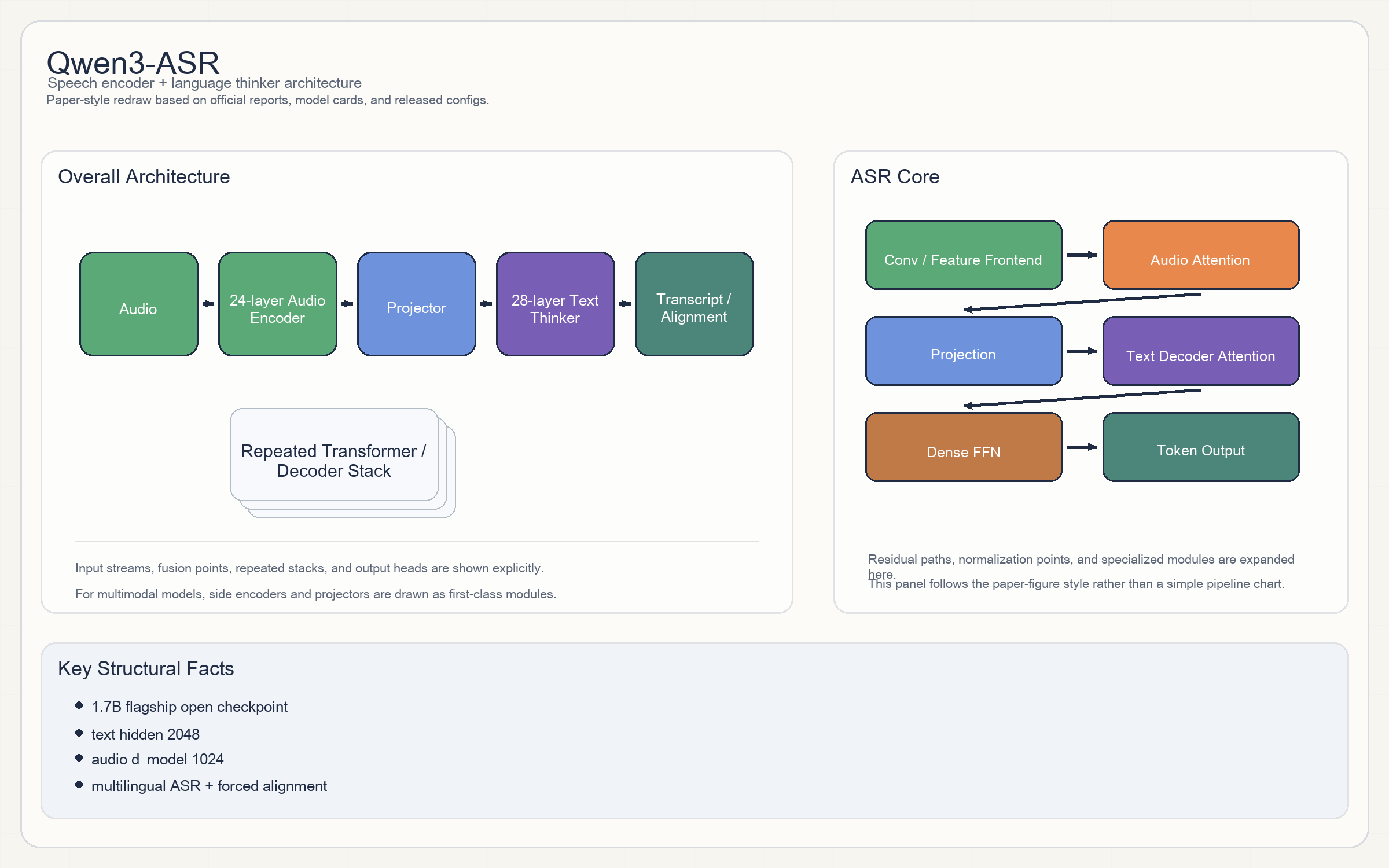
Release & Open Sources
- 发布时间:
2026-01-28。 - 形态:自动语音识别模型。
Architecture
Qwen3-ASR不是一个简单 Whisper 复刻。它显式拆成audio encoder + text thinker/decoder。- audio encoder 侧:
d_model = 1024、24encoder layers、16attention heads、FFN4096,激活函数GELU。 - 文本 thinker 侧:
2048 hidden / 28 layers / 16 heads / 8 KV heads / 65536 context,激活函数SiLU。 - 因此它本质上是一条
speech encoder -> language decoder的双塔生成架构。
Parameters & Hyperparameters
- 官方开源有
1.7B与0.6B两档,本节聚焦1.7B。 - audio branch:
24L / d_model 1024 / 16 heads。 - text branch:
28L / hidden 2048 / 16 heads / context 65536。
Training
- 官方 README 强调多语言、流式与强制对齐工具链。
- 完整 token / 小时数未在公开页完整披露。
Key Takeaways
- Qwen3-ASR 的价值在于:它把语音识别和语言推理衔接得更像一个可扩展生成模型,而不是孤立声学模型。
Links
- 官方仓库:QwenLM/Qwen3-ASR
- 模型页:Qwen/Qwen3-ASR-1.7B
- 阿里云文档:Qwen Speech Recognition
Qwen3-TTS
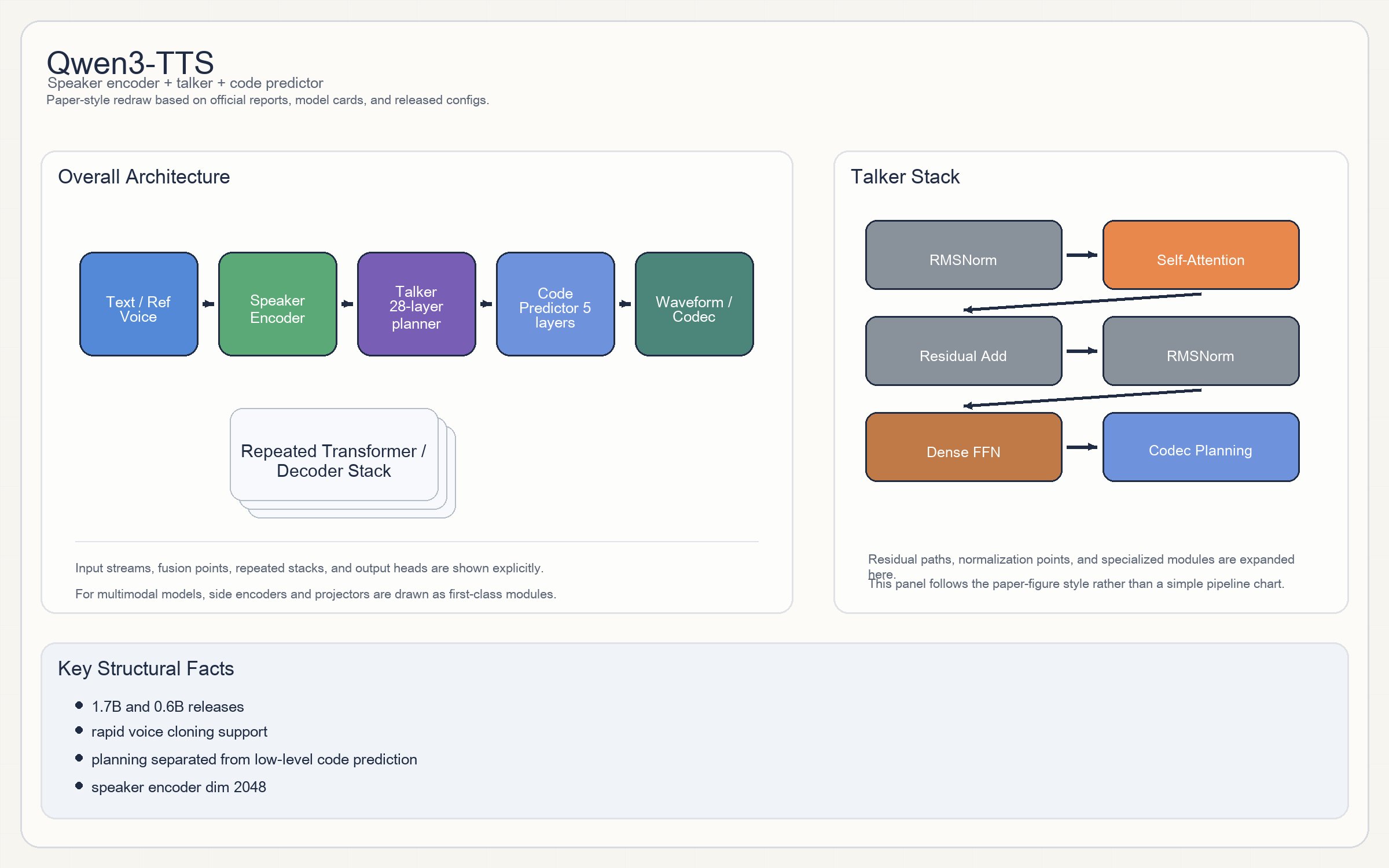
Release & Open Sources
- 发布时间:
2026-01-21。 - 形态:文本到语音家族。
Architecture
- 这条线明确拆成
speaker encoder + talker + code predictor。 talker是主语言生成器:2048 hidden / 28 layers / 16 heads / 8 KV heads / SiLU。code predictor更小:1024 hidden / 5 layers / 16 heads / 8 KV heads,负责声码序列或 codec 相关 token 预测。- 因此可以把它理解成“主语言声学规划器 + 小型语音 code head”的二级生成结构。
Parameters & Hyperparameters
- 官方开源的主模型有
1.7B与0.6B。 speaker encoder dim = 2048。talker:28 layers / hidden 2048 / intermediate 6144。code predictor:5 layers / hidden 1024 / heads 16。
Training
- 官方页面强调 rapid voice cloning、voice design 与实时 TTS。
- 更细的训练小时数 / 语料量未在公开 README 完整拆出。
Key Takeaways
- Qwen3-TTS 的结构重点在“把长程语言规划和低层语音 token 预测显式解耦”,这也是它适合 voice cloning / voice design 的原因。
Links
- 官方仓库:QwenLM/Qwen3-TTS
- 模型页:Qwen/Qwen3-TTS-12Hz-1.7B-Base
- 阿里云文档:Qwen TTS Realtime
Mistral AI
Voxtral Mini 4B Realtime
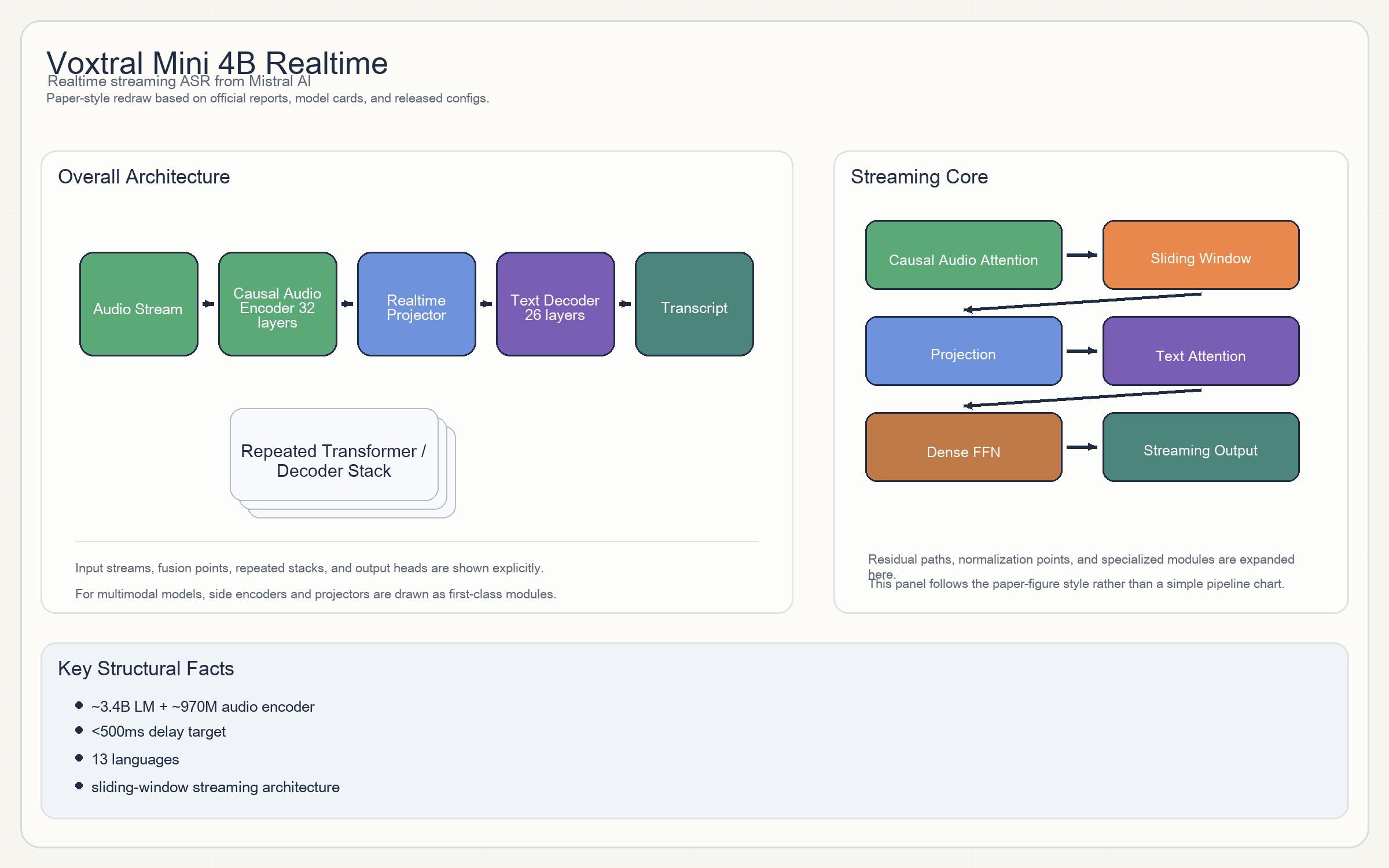
Release & Open Sources
- 发布时间:
2026-01-21。 - 形态:实时流式语音转写模型。
Architecture
- 整体是
causal audio encoder + text decoder。 - 音频侧:
32层、1280 hidden、32 heads、128 mel bins,并且使用sliding window = 750做流式建模。 - 文本侧:
26层、3072 hidden、32 heads / 8 KV heads、sliding window = 8192。 - 官方特别强调 audio encoder 是
trained from scratch with causal attention enabling streaming capability。
Parameters & Hyperparameters
- 官方拆解:约
3.4B语言模型 +970M音频编码器,总计约4B。 - 支持
<500ms延迟。 audio_length_per_tok = 8,downsample_factor = 4。
Training
- 技术报告
arXiv:2602.11298。 - 公开材料重点放在 streaming accuracy / latency tradeoff,不是大规模 token 数。
Key Takeaways
- Voxtral Realtime 是 2026 Q1 少数把“真正的流式、低延迟、开源 speech model”讲清楚的工业级 release。
Links
StepFun / 阶跃星辰
Step-Audio-R1.1
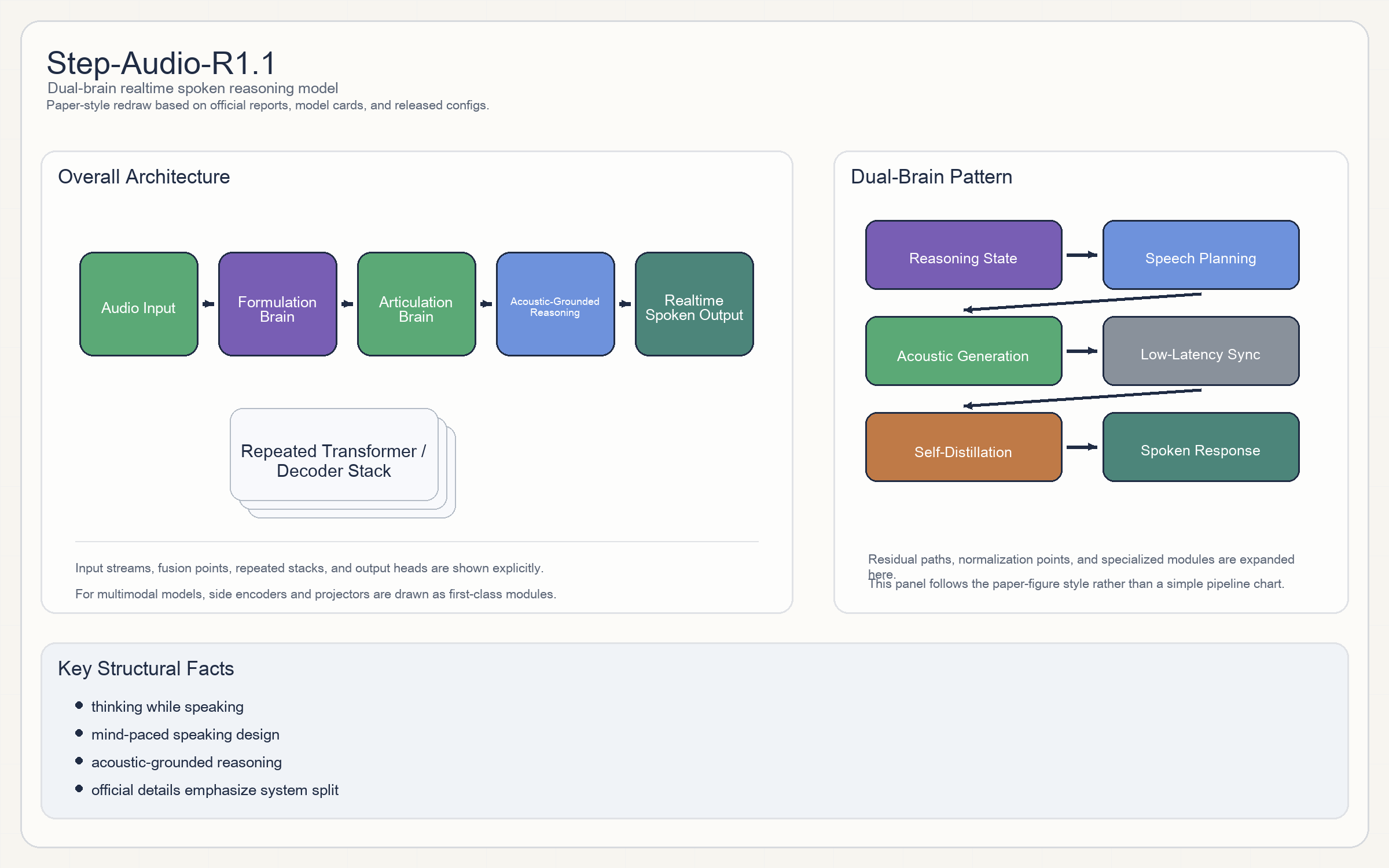
Release & Open Sources
- 发布时间:
2026-01-14。 - 形态:实时对话与音频推理模型。
Architecture
- 官方最强调的是
Dual-Brain Architecture:Formulation Brain负责高层 reasoning;Articulation Brain负责低延迟语音输出。
- 这不是普通 ASR/TTS 级联,而是显式尝试“thinking while speaking”。
- 模型同时强调
acoustic-grounded reasoning,说明它不是先把声音全转成文字再思考,而是部分直接在声学表示上推理。
Parameters & Hyperparameters
- 公开 README 对系统结构描述比逐层 config 更完整。
- 具体层数、heads、hidden size 在公开页没有像 Step3-VL 那样完整展开。
Training
- 官方重点是两条:
Mind-Paced Speaking和iterative self-distillation。 - 这说明 R1.1 的改进主要来自后训练和推理规划,而不是更大的底座。
Key Takeaways
- Step-Audio-R1.1 值得关注的地方是“推理”和“说话”被显式拆成两套 brain,这和大多数实时语音模型很不一样。
Links
- 模型页:stepfun-ai/Step-Audio-R1.1
- Studio:StepFun Audio Studio
- GitHub 组织页:stepfun-ai
Microsoft
VibeVoice-ASR
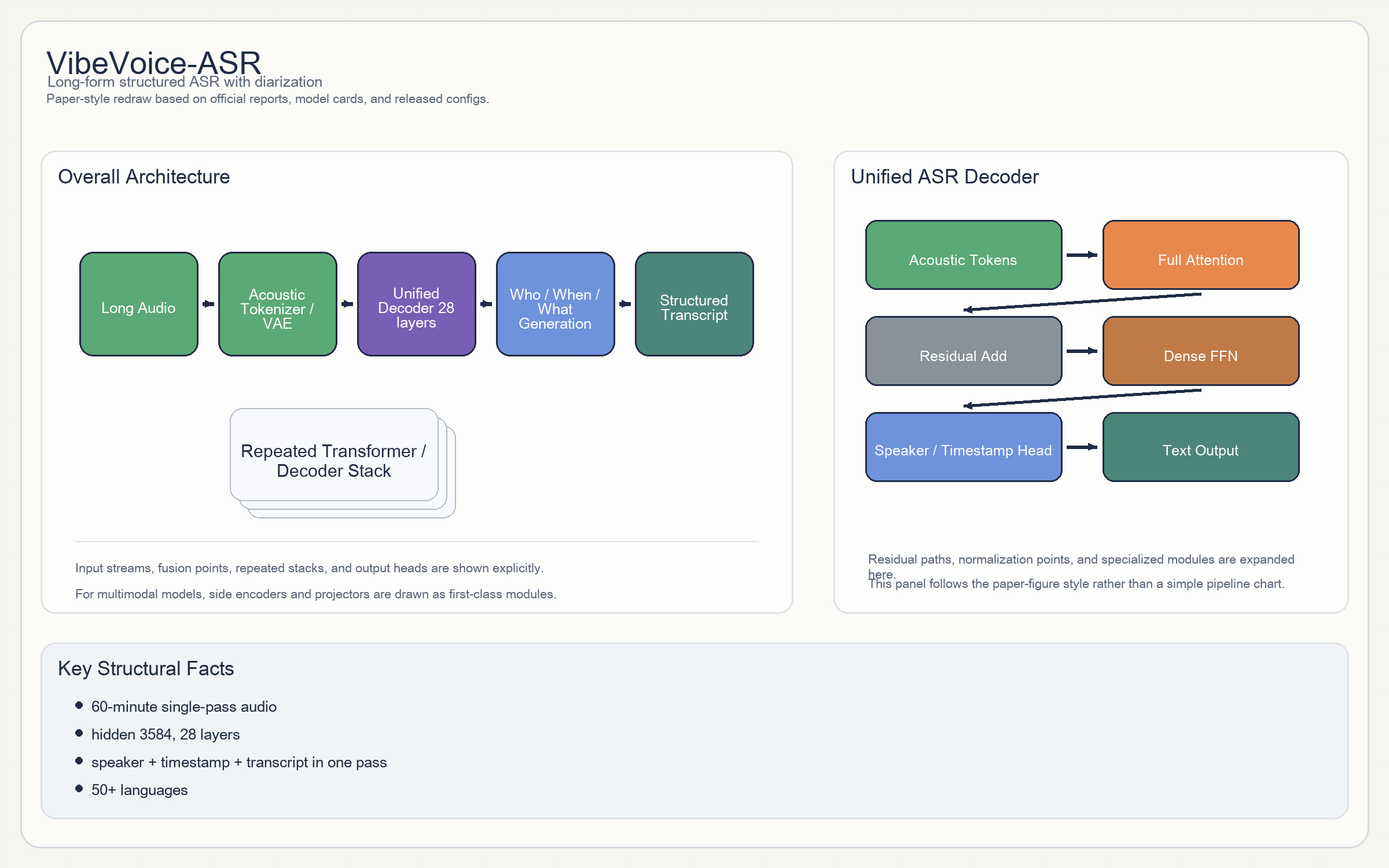
Release & Open Sources
- 发布时间:
2026-01-21。 - 形态:长音频、带说话人和时间戳结构化输出的统一 ASR 模型。
Architecture
- VibeVoice-ASR 是
acoustic tokenizer + unified decoder路线。 - 它带一个明确的
acoustic tokenizer / VAE,之后由长上下文 decoder 一次性生成Who / When / What。 - decoder config:
3584 hidden / 28 layers / 28 heads / 4 KV heads / 131072 context,激活函数SiLU。 - acoustic tokenizer 则是卷积 + depthwise mixer 路线,并不是简单 mel frontend。
Parameters & Hyperparameters
- 主 decoder:
28 layers / hidden 3584 / intermediate 18944。 - acoustic tokenizer:
VAE dim 64。 - 支持单次
60 分钟音频输入。
Training
- 技术报告
arXiv:2601.18184。 - 官方重点是长音频单次处理、说话人分离、热词支持、多语言。
Key Takeaways
- VibeVoice-ASR 最强的点不是 WER 单项,而是把 diarization、timestamps 和 transcription 统一成一次性生成任务。
Links
- 技术报告:arXiv:2601.18184
- 官方仓库:microsoft/VibeVoice
- 模型页:microsoft/VibeVoice-ASR
IBM
Granite 4.0 1B Speech
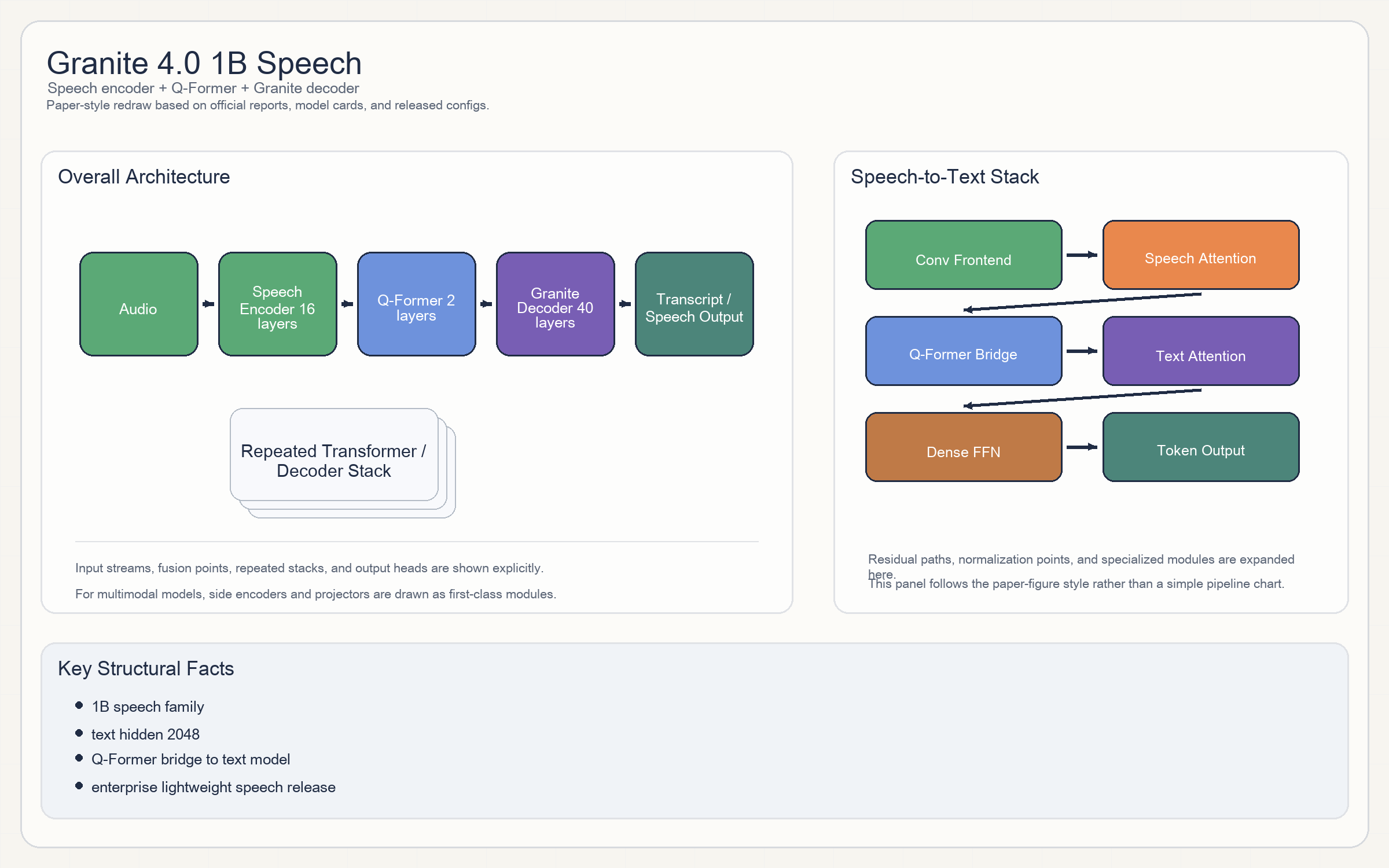
Release & Open Sources
- 发布时间:
2026-02-27。 - 形态:紧凑 speech foundation model。
Architecture
- 结构是
speech encoder + Q-Former projector + Granite text decoder。 - speech encoder:
16层、1024 hidden、8 heads、卷积核15。 - projector 是
BLIP-2 / Q-Former风格:2层、1024 hidden、16 heads。 - 文本侧是
Granite 4.0 1B base:2048 hidden / 40 layers / 16 heads / 4 KV heads。
Parameters & Hyperparameters
- family 规模约
1B。 - 文本 context
4096。 - speech encoder 输入维度
160,输出维度348,downsample rate5。
Training
- README 直接给了两篇技术报告:
2505.08699与2603.11243。 - 并列出了 Common Voice、MLS、LibriSpeech、VoxPopuli、AMI、YODAS 等大量语音语料。
Key Takeaways
- Granite 4.0 1B Speech 更像一个面向企业 / 开发者的轻量开源语音底座:结构清晰、依赖少、训练数据透明度相对高。
Links
- 模型页:ibm-granite/granite-4.0-1b-speech
- IBM Granite 门户:IBM Granite
- 相关论文:arXiv:2603.11243
Closing Thoughts
如果把 2026 Q1 的开源模型放在一起看,有几条趋势特别清楚。
- 第一,
MoE已经从“参数扩张工具”变成了默认工程选项。MiMo-V2-Flash、Kimi-K2.5、MiniMax-M2.5、Qwen3-Coder-Next、Qwen3.5 MoE、GLM-5、Step-3.5-Flash、Nemotron-3 Super几乎都在不同程度上走向 sparse routing。 - 第二,attention 正在持续异构化。
MLA、linear / DeltaNet + periodic full attention、hybrid SWA/GA、Mamba + Attention不再是少数实验架构,而是主线开源模型的现实选择。 - 第三,后训练越来越“agent-native”。很多 2026 模型的核心卖点已经不是 SFT,而是
agentic RL、multi-environment RL、computer-use、formal proving、tool-integrated reasoning。 - 第四,模态融合在分化。通用基础模型倾向于早融合;文档 / OCR 模型倾向于更轻、更窄的 connector;语音模型则普遍显式拆成
encoder + language model或reasoning brain + articulation brain。
从写作角度说,2026 Q1 很难再用“开源模型就是某家 7B / 70B transformer”去概括。现在真正重要的是:它到底把哪些结构变量拿出来优化了,优化目标是吞吐、长上下文、agent RL、视觉 token 效率,还是音频流式交互。
References
[1] Xiaomi MiMo, MiMo-V2-Flash Blog.
[2] Xiaomi MiMo, MiMo-V2-Flash Technical Report.
[3] Moonshot AI, Kimi K2.5 Blog.
[4] Moonshot AI, Kimi K2.5 Technical Report.
[5] Meituan LongCat, LongCat-Flash-Thinking-2601.
[6] Meituan LongCat, LongCat-Flash-Lite Technical Report.
[7] Meituan LongCat, LongCat-Flash-Prover Technical Report.
[8] MiniMax, MiniMax M2.5.
[9] MiniMax, Forge: Scalable Agent RL Framework and Algorithm.
[10] Qwen, Qwen3-Coder-Next Blog.
[11] Qwen, Qwen3.5 Blog.
[12] Z.ai, GLM-5 Blog.
[13] Z.ai, GLM-OCR Technical Report.
[14] Z.ai, GLM-Image Blog.
[15] DeepSeek, DeepSeek-OCR-2 Technical Report.
[16] Mistral AI, Voxtral Mini 4B Realtime.
[17] NVIDIA, NVIDIA Nemotron-3 Super Technical Report.
[18] StepFun, Step 3.5 Flash.
[19] StepFun, STEP3-VL-10B Technical Report.
[20] Microsoft, VibeVoice-ASR Technical Report.
[21] Meituan, EvoCUA Technical Blog.
[22] Meituan, EvoCUA Technical Report.
[23] IBM Granite, granite-4.0-3b-vision.
[24] IBM Granite, granite-4.0-1b-speech.